Переважно написана на мові Go колишніми співробітниками компанії Google. Прототипом Prometheus виступала моніторингова система Borgmon. Ця моніторингова система має наступні переваги/недоліки/особливості:
- багатовимірну модель даних, з часовими рядами, що ідентифікуються назвою метрики та парою ключ/значення;
- гнучку мову запитів, що використовує цю модель;
- pull-модель роботи серверу, збирання даних відбувається опитуванням вузлів, що моніторяться, по протоколу HTTP (хоча існує також Pushgateway, що працює по push-моделі і призначений для збирання метрик з недовговічних вузлів);
- відсутність залежності від розподілених віддалених сховищ; кожен вузол Prometheus є автономним;
- об'єкти моніторингу можуть додаватись вручну до основного конфігураційного файлу Prometheus чи автоматично через service discovery (Consul, API/теги AWS, GCP, Kubernetes, Openstack та інші).
Як вже було згадано, Prometheus - це моніторингова система, що працює за pull-моделлю. Тобто сервер опитує власноруч кожен вузол, що потребує моніторингу. На думку авторів проекту, така модель дещо краща за push-модель (коли метрики відправляються самостійно на сервер моніторингу без жодних запитів). Чудовим прикладом останньої є Sensu, про яку я вже писав декілька років тому.
Prometheus - модульна моніторингова система, її підсистеми за потреби можуть бути замінені на альтернативні. Проте основні елементи Prometheus наступні:
- Prometheus server (Web UI/API, TSDB) - основний сервер моніторингу, запитує та зберігає всі метрики від клієнтів, надає базову веб-панель запитів та API
- Exporters - компоненти, що виступають джерелом даних для Prometheus сервера. Зазвичай працюють на стороні клієнта, але є і вийнятки, наприклад, Blackbox exporter. Є купа готових як офіційних, так і сторонніх рішень для збирання метрик з MySQL, RabbitMQ та ін.
- Alertmanager - підсистема, що забезпечує групування, стримування, дедуплікацію, маршрутизацію повідомлень від систем на зразок серверу Prometheus. Також має базову веб-панель, де можна відфільтрувати повідомлення, призупинити їх надсилання при певних умовах та ін.
- Pushgateway - служба-посередник, що на відміну від Prometheus server, отримує метрики від вузлів і вже потім пересилає їх на основний сервер. Не обов'язковий компонент, але може бути корисний у разі моніторингу сервісів із коротким життєвим циклом чи програм, що не надають відкритий порт для отримання метрик основним сервером.
- Grafana - веб-панель на Go/NodeJS для побудови та відображення метрик. Вміє працювати з Prometheus "із коробки".

credits https://prometheus.io/
Замість власної бази для метрик Prometheus може використовувати сторонні: деякі лише на запис (тобто ретрансляцію даних до сторонньої бази) чи одночасно на запис і читання (наприклад, InfluxDB).
Всі пакети Prometheus можна знайти в офіційних репозиторіях Ubuntu починаючи з версії 16.04, для попередніх LTS версій можна скористатись сторонніми неофіційними, наприклад цими https://github.com/jtyr/prometheus-deb чи цими http://deb.robustperception.io/. Проте тут можуть бути не останні релізи, тому ми будемо запускати бінарні файли з репозиторіїв проекту на Github. Список останніх версіх усіх офіційних компонентів Prometheus можна знайти на офіційному сайті.
У цій статті буде розглянута інсталяція всіх компонентів Prometheus на один хост, але вони можуть бути з легкістю рознесені на групу серверів. У якості операційної системи було обрано Ubuntu 16.04.
1. INSTALLATION OF PROMETHEUS SERVER
Завантажуємо та розпакуємо архів із останнім релізом сервера:
# wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz
# tar xvzf prometheus-2.4.3.linux-amd64.tar.gz
Створимо користувача від імені якого буде працювати сервіс:
# adduser --no-create-home --disabled-login --shell /bin/false --gecos "Prometheus Monitoring User" prometheus
Та необхідні директорії для розміщення файлів програми:
# mkdir /etc/prometheus /var/lib/prometheus
Скопіюємо вже розпаковані файли архіву:
# cp prometheus-2.4.3.linux-amd64/prometheus prometheus-2.4.3.linux-amd64/promtool /usr/local/bin/
# cp -r prometheus-2.4.2.linux-amd64/consoles prometheus-2.4.2.linux-amd64/console_libraries /etc/prometheus
І нарешті виставимо коректні права:
# chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus /usr/local/bin/prometheus /usr/local/bin/promtool
Опишемо конфігураційний файл серверу Prometheus:
# vim /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
Було вказано глобальний інтервал збору метрик кожні 15 секунд у разі, якщо інший не задекларовано нижче для кожної конкретної задачі. У секції scrape_configs поки лише додана задача моніторингу самого себе (job_name: 'prometheus'), де інтервал було знижено до 5 секунд.
Створимо файл запуску програми systemd, додамо Prometheus до автозавантаження та запустимо:
# vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus/ \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload
# systemctl enable prometheus
# systemctl start prometheus
# systemctl status prometheus
Після чого на порту 9090 буде запущено Web UI Prometheus:

Перевіримо список вузлів, що вже моніторятся (targets в термінології Prometheus). Тут поки має бути описаний лише один сервер:

Одразу після установки в сервера можна запросити деякі дані, наприклад, кількість відкритих файлових дескрипторів:


Хорошим тоном є завжди вказувати ім'я задачі ({job="prometheus"}), що безпосередньо стосується запиту. Він збігається із job_name зі scrape_configs секції основного файлу конфігурації Prometheus.
Як я вже говорив, однією із переваг Prometheus над іншими системами моніторингу є гнучка мова запитів, що дозволяє не лише демонструвати дані часових серій, а й виконувати логічні функції над ними. Це дуже зручно для правильної інтерпретації даних, що саме відбувається із системами. Для більшого розуміння можливостей логічних функцій рекомендую переглянути наступні статті одного із основних розробників Prometheus:
How To Query Prometheus on Ubuntu 14.04 Part 1
How To Query Prometheus on Ubuntu 14.04 Part 2
та отримати нормальну математичну освіту.
2. INSTALLATION OF NODE EXPORTER
Node Exporter - це сервер надання та збору базових метрик операційної системи, серед яких, наприклад, детальна статистика роботи процесора, пам'яті, дисків, мережевої системи і купа всього іншого. Всі перевірки діляться на ті, що увімкнені по замовчуванню та котрі необхідно активувати за потреби.
Аналогічно завантажимо останній реліз Node Exporter з офіційного Github-у проекту, розпакуємо архів, створимо окремого користувача, скопіюємо необхідні файли та виставимо коректні права для роботи:
# adduser --no-create-home --disabled-login --shell /bin/false --gecos "Node Exporter User" node_exporter
# wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz
# tar xvzf node_exporter-0.16.0.linux-amd64.tar.gz
# cp node_exporter-0.16.0.linux-amd64/node_exporter /usr/local/bin/
# chown node_exporter:node_exporter /usr/local/bin/node_exporter
Створимо systemd файл запуску для Node Exporter:
# vim /etc/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
Якщо кількість перевірок за замовчуванням здається надлишковою, ExecStart параметр можна відредагувати на наступний:
ExecStart=/usr/local/bin/node_exporter --collectors.enabled meminfo,loadavg,filesystem
У такому разі будуть активовані лише збори метрик по пам'яті, завантаженню та файловій системі. Тут є повний список можливих опцій.
Додамо новий сервіс в автозавантаження та запустимо:
# systemctl daemon-reload
# systemctl enable node_exporter
# systemctl start node_exporter
# systemctl status node_exporter
Щоб статистика, котру надає Node Exporter, збиралась Prometheus-ом, його потрібно додати до секції scrape_config у якості нового задачі:
# vim /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
Після змін конфігураційних файлів Prometheus, його необхідно перевантажувати. Тепер у web-панелі Prometheus має з'явитись новий target та нові метрики:


Статистику, що надає Node Exporter також можна побачити в браузері на 9100 порту вузла, де його було запущено (і це стосується не лише Node Exporter-а):

Цей Exporter надає базові метрики роботи операційної системи, тому логічно буде проінсталювати його на кожен сервер. Із появою нових вузлів секція задачі node_exporter серверу Prometheus має бути доповнена:
# vim /etc/prometheus/prometheus.yml
...
- job_name: 'node_exporter'
scrape_interval: 5s
static_configs:
- targets:
- localhost:9100
- second-server:9100
- third-server:9100
Або ж для цього може бути використаний discovery сервіс Consul.
3. INSTALLATION OF BLACKBOX EXPORTER
Blackbox exporter дозволяє генерувати метрики роботи HTTP(S), DNS, TCP та ICMP серверів/сервісів. Цей експортер можна встановити як на окремому сервері, так і на тому ж головному сервері Prometheus (так ми і зробимо), адже перевіряє він віддалені, зазвичай доступні всім вузлам мережі, ресурси.
Спершу завантажимо останній реліз експортеру, розпакуємо його та скопіюємо бінарний файл до /usr/local/bin/:
# wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.12.0/blackbox_exporter-0.12.0.linux-amd64.tar.gz
# tar xvzf blackbox_exporter-0.12.0.linux-amd64.tar.gz
# cp blackbox_exporter-0.12.0.linux-amd64/blackbox_exporter /usr/local/bin/
Створимо окремого користувача blackbox_exporter, без можливості логінитись на сервер і домашньої директорії:
# adduser --no-create-home --disabled-login --shell /bin/false --gecos "Blackbox Exporter User" blackbox_exporter
Створимо директорію для збереження конфігурації Blackbox exporter та опишемо конфігурацію для нього:
# mkdir /etc/blackbox
# vim /etc/blackbox/blackbox.yml
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_status_codes: [] # Defaults to 2xx
method: GET
preferred_ip_protocol: ip4
Отже ми створили новий модуль http_2xx, що по http-протоколу (prober у термінології експортера) буде опитувати вузли, котрі ми опишемо пізніше в основному конфігураційному файлі prometheus.yml. Він вважатиме, що вузли працюють коректно, якщо у разі GET-запиту вузол віддаватиме 200-ті коди повернення. Це досить примітивний приклад використання даного експортеру, проте для прикладу згодиться. У разі ж додаткової зацікавленості пропоную ознайомитись із цим прикладом конфігурації.
Установимо коректні права на новостворені директорії для Blackbox Exporter:
# chown -R blackbox_exporter:blackbox_exporter /etc/blackbox
# chown blackbox_exporter:blackbox_exporter /usr/local/bin/blackbox_exporter
Щоб сервіс було зручно запускати/зупиняти опишемо для нього systemd конфігурацію:
# vim /etc/systemd/system/blackbox_exporter.service
[Unit]
Description=Prometheus blackbox exporter
After=network.target auditd.service
[Service]
User=blackbox_exporter
Group=blackbox_exporter
Type=simple
ExecStart=/usr/local/bin/blackbox_exporter --config.file=/etc/blackbox/blackbox.yml
Restart=on-failure
[Install]
WantedBy=default.target
І додамо в автозапуск та завантажимо:
# systemctl daemon-reload
# systemctl enable blackbox_exporter
# systemctl start blackbox_exporter
# systemctl status blackbox_exporter
Створимо нову задачу на сервері Prometheus:
# vim /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- https://prometheus.io/
- http://localhost:8080
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: localhost:9115 # The blackbox exporter's real hostname:port.
На порту 8080 серверу localhost має бути запущено веб-сервер, який можна встановити та налаштувати використовуючи будь яку з наступних утиліт https://gist.github.com/willurd/5720255, наприклад:
$ echo "<h1>Say hello to Prometheus</h1>" > index.html
$ nohup busybox httpd -f -p 8080 &
Після перевантаження серверу Prometheus зможемо спостерігати нові target-и та метрики опитування перелічених вище веб-ресурсів:


4. ALERTING
4.1. Installation Of Alertmanager
Alertmanager - компонент оповіщення моніторингової системи Prometheus. Інсталяція аналогічна іншим компонентам:
# wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz
# tar xvzf alertmanager-0.15.2.linux-amd64.tar.gz
Скопіюємо щойно розархівовані бінарні файли:
# cp alertmanager-0.15.2.linux-amd64/alertmanager /usr/local/bin/
# cp alertmanager-0.15.2.linux-amd64/amtool /usr/local/bin/
Створимо однойменного користувача для нового компоненту:
# adduser --no-create-home --disabled-login --shell /bin/false --gecos "Alertmanager User" alertmanager
Та створимо директорії для майбутніх конфігураційних файлів:
# mkdir -p /etc/alertmanager/{data,template}
Виставимо нового власника файлів:
# chown alertmanager:alertmanager /usr/local/bin/alertmanager /usr/local/bin/amtool
# chown -R alertmanager:alertmanager /etc/alertmanager
Створимо базову конфігурацію Alertmanager, що відправлятиме повідомлення на пошту (у даному випадку приведена конфігурація відправлень через поштовий сервіс Gmail) у разі появи проблем:
# vim /etc/alertmanager/alertmanager.yml
global:
smtp_smarthost: 'smtp.gmail.com:587'
smtp_from: 'somebody@gmail.com'
smtp_auth_identity: 'somebody@gmail.com'
smtp_auth_username: 'somebody@gmail.com'
smtp_auth_password: 'my_hard_password'
route:
group_by: ['instance', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: team-1
receivers:
- name: 'team-1'
email_configs:
- to: 'my_company_email@company.team'
Отже, нові повідомлення будуть групуватись на протязі 30 секунд (параметр group_wait) по полям instance та severity і будуть відправлятись одним листом команді team-1 з поштою my_company_email@company.team використовуючи smtp параметри, що приведені в секції global. При появі нових повідомлень в тій же групі Alertmanager через 5 хв (group_interval) відправить нове повідомлення.
Надалі, якщо нові повідомлення в групі з'являтись не будуть і проблеми будуть не вирішені, попередні повідомлення будуть дублюватись із частотою раз в 3 години (параметр repeat_interval). Із однієї сторони це буде вносити затримки в швидкість інформування про наявні проблеми, а з іншої це зменшить головний біль від неймовірної кількості повідомлень у разі падіння якогось із вузлів/сервісів. Гарний приклад конфігурації з купою можливих опцій як завжди можна знайти в офіційному репозиторії та документації.
Окрім повідомлень на пошту, Alertmanager підтримує і інші варіанти сповіщень, серед яких Slack, Hipchat, PagerDuty та інші.
Нарешті створимо systemd скрипт для запуску Alertmanager та запустимо та додамо його в автозавантаження:
# vim /etc/systemd/system/alertmanager.service
[Unit]
Description=Prometheus Alert Manager service
Wants=network-online.target
After=network.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
ExecStart=/usr/local/bin/alertmanager --config.file /etc/alertmanager/alertmanager.yml --storage.path /etc/alertmanager/data
Restart=always
[Install]
WantedBy=multi-user.target
# systemctl daemon-reload
# systemctl enable alertmanager
# systemctl start alertmanager
# systemctl status alertmanager
4.2. Connecting Alertmanager to Prometheus and creating new alerting rule
Створимо перше правило перевірки роботи вузлів:
# vim /etc/prometheus/alert.rules.yml
groups:
- name: alert.rules
rules:
- alert: EndpointDown
expr: probe_success == 0
for: 10s
labels:
severity: "critical"
annotations:
summary: "Endpoint {{ $labels.instance }} down"
Якщо змінна probe_success, що потрапить до Prometheus сервера, буде рівна 0 (перевірка вузла не зможе бути виконана) на протязі 10 секунд, буде створено оповіщення, що буде направлено до сервером моніторингу до Alertmanager.
Кожні нові правила перед застосовуванням, завдяки утиліти promtool, можна перевірити в командному рядку:
# promtool check rules /etc/prometheus/alert.rules.yml
Checking /etc/prometheus/alert.rules.yml
SUCCESS: 1 rules found
Цей список правил та адреса Alertmanager-а має бути описана в основному конфігураційному файлі Prometheus, після чого зміни будуть застосовані після перезавантаження серверу моніторингу:
# vim /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
rule_files:
- alert.rules.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
...
# systemctl restart prometheus
Для отримання нового сповіщення, зупинимо раніше запушений веб-сервер:
# killall busybox
З часом Prometheus помітить проблему:

І надішле її сервісу Alertmanager:
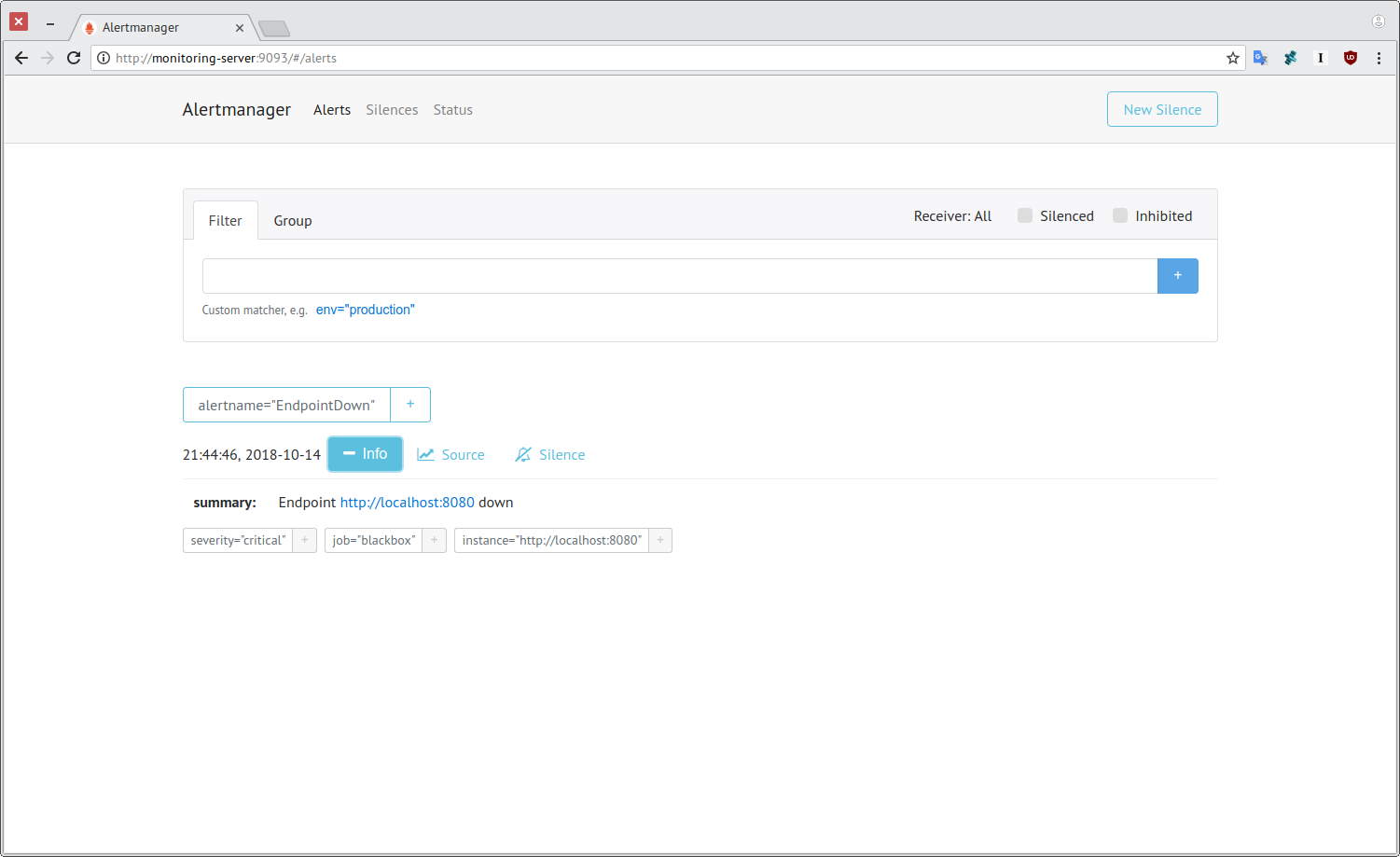
Останній, використовуючи описані в alertmanager.yml правила маршрутизації повідомлень, надішле необхідні оповіщення. У нашому випадку на пошту:

Для перегляду усіх активних сповіщень Alertmanager можна скористуватись консольною утилітою amtool:
$ amtool alert query --alertmanager.url http://localhost:9093
Alertname Starts At Summary
EndpointDown 2018-10-14 17:44:46 EDT Endpoint http://localhost:8080 down
Окрім того з її допомогою можна призупинити отримання повідомлень, фільтрувати оповіщення в залежності від проблемного вузла, додавати коментарі до власних дій і т.п., наприклад:
$ amtool silence add instance=http://localhost:8080 --duration 3h --author "John Doe" --comment "Investigating the progress" --alertmanager.url http://localhost:9093
Звісно, це ж саме можна зробити і у веб-панелі Alertmanager, що працює на 9093 порту.
4.3. Installing Karma (alerting panel)
Опціонально можна спробувати панель Karma, вона більш наочно демонструє всі доступні сповіщення Alertmanager, має деякі додаткові функції і може чудово підійти для демонстрації на великих моніторах.
# wget https://github.com/prymitive/karma/releases/download/v0.14/karma-linux-amd64.tar.gz
# tar xvfz karma-linux-amd64.tar.gz
# cp karma-linux-amd64 /usr/local/bin/karma
# adduser --no-create-home --disabled-login --shell /bin/false --gecos "Karma for Alertmanager" karma
# chown karma:karma /usr/local/bin/karma
Ну і як завжди опишемо сервіс в systemd та додамо його в автозавантаження:
# vim /etc/systemd/system/karma.service
[Unit]
Description=Karma Panel for Alertmanager
After=network.target auditd.service
[Service]
User=karma
Group=karma
Type=simple
ExecStart=/usr/local/bin/karma --alertmanager.uri http://localhost:9093
Restart=on-failure
[Install]
WantedBy=default.target
# systemctl daemon-reload
# systemctl enable karma
# systemctl start karma
# systemctl status karma
Онлайн демо можна знайти за посиланням https://karma-demo.herokuapp.com/

5. INSTALLATION OF GRAFANA
Grafana - чудова веб-панель для демонстрації графічних даних. Досить давно я писав про неї у якості фронтенда до Graphite. Наразі вона стала ще більш універсальною і навчилась напряму працювати з Promtheus. Установимо її і додамо до автозавантаження:
# echo 'deb https://packagecloud.io/grafana/stable/debian/ stretch main' > /etc/apt/sources.list.d/grafana.list
# curl https://packagecloud.io/gpg.key | apt-key add -
# apt update
# apt install grafana -y
# systemctl daemon-reload
# systemctl enable grafana-server
# systemctl start grafana-server
Логінимось в Grafana за 3000 портом та додаємо нове джерело даних для time series:


6. SENDING DATA TO GRAPHITE (WRITE REMOTE STORAGE)
Загалом в цій моніторинговій системі є мінус - вона, як і багато інших, не призначена для дійсно тривалого зберігання метрик (мається на увазі роки). У базі даних Prometheus немає вбудованого rollup/storage aggregation, тобто він не може зменшувати точність для старіших даних. Чим більше даних - тим більш неповоротким ставатиме Prometheus і тим більше розпухатиме диск.
Власне нічого критичного в цьому немає і з цим можна жити. Як обхідний шлях можна скористатись можливістю ретранслювати дані Prometheus в віддалений інстанс Graphite. Для цього необхідно скомпілювати remote_storage_adapter:
# add-apt-repository ppa:gophers/archive
# apt update
# apt install golang-1.10-go
# export PATH=$PATH:/usr/lib/go-1.10/bin
# go version
go version go1.10 linux/amd64
# mkdir -p github.com/prometheus
# git clone https://github.com/prometheus/prometheus.git github.com/prometheus/prometheus
# go get -d -v github.com/prometheus/prometheus/documentation/examples/remote_storage/remote_storage_adapter
# go build github.com/prometheus/prometheus/documentation/examples/remote_storage/remote_storage_adapter
remote_storage_adapter після запуску стане доступним для підключень по 9201 порту:
# chmod +x remote_storage_adapter
$ nohup ./remote_storage_adapter -graphite-address=graphite-carbon-host:2003 &
Звісно також не завадить описати цей процес в systemd. Додамо опцію в prometheus.yml для записів в remote_storage_adapter:
# vim /etc/prometheus/prometheus.yml
...
remote_write:
- url: "http://localhost:9201/write"
...
Після чого необхідно перевантажити Prometheus.
Якщо ж в Graphite стеку у якості демона збору метрик працює carbon-clickhouse (тобто стек із ClickHouse OLAP базою всередині), то метрики Prometheus можна одразу пересилати на його віддалений 2006 порт. Відповідно remote_storage_adapter не буде потрібний.
Стороння реалізація remote_storage_adapter підтримує як читання так і запис із Graphite, і має підтримку тегів.
Окрім Graphite, у якості віддаленого місця зберігання (а іноді і читання) метрик можна звісно використовувати і інші рішення, на зразок того ж InfluxDB, PostgreSQL, Kafka та інші.
Посилання:
https://gist.github.com/petarGitNik/18ae938aaef4c4ff58189df8a4fc7de9
https://www.digitalocean.com/community/tutorials/how-to-install-prometheus-on-ubuntu-16-04
https://www.digitalocean.com/community/tutorials/how-to-use-alertmanager-and-blackbox-exporter-to-monitor-your-web-server-on-ubuntu-16-04
https://rahulwa.com/post/monitoring-using-prometheus/
https://www.digitalocean.com/community/tutorials/how-to-query-prometheus-on-ubuntu-14-04-part-1
https://www.digitalocean.com/community/tutorials/how-to-query-prometheus-on-ubuntu-14-04-part-2
https://habr.com/post/308610/
https://github.com/line/promgen
https://habr.com/company/selectel/blog/275803/
https://github.com/prometheus/alertmanager/blob/master/doc/examples/simple.yml
https://www.robustperception.io/sending-email-with-the-alertmanager-via-gmail
https://prometheus.io/docs/alerting/configuration/
https://www.slideshare.net/brianbrazil/prometheus-overview
https://www.slideshare.net/brianbrazil/prometheus-and-docker-docker-galway-november-2015
https://www.percona.com/live/e17/sessions/using-prometheus-with-influxdb-for-metrics-storage
https://pierrevincent.github.io/2017/12/prometheus-blog-series-part-1-metrics-and-labels/
Немає коментарів:
Дописати коментар