Kops (Kubernetes Operation) - це програмне забезпечення написане на мові Go, що дозволяє вирішувати проблеми установки та обслуговування кластеру Kubernetes. Серед його особливостей та переваг можна відзначити наступні:
- Підтримує установку кластерів для cloud-платформ AWS, GCE (beta статус), DigitalOcean (зі значними обмеженнями), VMWare Vsphere (alpha статус).
- Здатний інсталювати кластери високої доступності (HA), може налаштовувати мульти-майстер конфігурації з урахуванням можливостей та сервісів cloud-платформ.
- Підтримує ідемпотентність операцій над кластером; перед застосуванням змін здатен інформувати, що саме буде змінено (dry-runs).
- Опис інфраструктури може зберігати в Terraform темплейтах чи CloudFormation.
- Підтримує установку додатків Kubernetes (Dashboard, EFK, Prometheus Operator, Ingress і інші). У свою чергу вони можуть бути дещо змінені задля кращої інтеграції з функціоналом cloud-платформи.
- Налаштування зберігає в форматі YAML.
- Підтримує 8 різних плагінів для опису оверлейної мережі pod-to-pod/pod-to-service (CNI Networking)
1. PREREQUIREMENTS
Для того щоб перейти до установки Kubernetes кластеру спочатку необхідно встановити awscli та kops. Перший розповсюджується як python-пакет, котрий із легкістю можна встановити через pip:
$ pip install awscli --upgrade --user
$ aws --version
aws-cli/1.15.37 Python/3.6.3 Linux/4.13.0-43-generic botocore/1.10.37
Після чого awscli необхідно налаштувати вказавши користувача профілю AWS з повним адмінським аккаунтом:
$ aws configure
AWS Access Key ID [None]: MYSECRETKEYID
AWS Secret Access Key [None]: MYSERETKEYVALUE
Default region name [None]: us-east-1
Default output format [None]:
Якщо ж такий користувач відсутній, наступний документ допоможе із його створенням https://docs.aws.amazon.com/IAM/latest/UserGuide/getting-started_create-admin-group.html.
Він надалі буде необхідний для створення окремого kops користувача з обмеженими правами. Після налаштування дані користувача будуть записані до ~/.aws/credentials та ~/.aws/config.
Завантажимо kops. Перейдемо за наступним посиланням та установимо останній реліз:
$ wget -O kops https://github.com/kubernetes/kops/releases/download/$(curl -s https://api.github.com/repos/kubernetes/kops/releases/latest | grep tag_name | cut -d '"' -f 4)/kops-linux-amd64
$ chmod +x kops
$ sudo mv kops /usr/local/bin/
$ kops version
Version 1.9.1 (git-ba77c9ca2)
Окрім цього kops доступний і для відмінних від Linux операційних систем..
Kubectl необхідний лише на етапі управління примітивами Kubernetes, проте не бачу причин переносити його установку на потім:
$ wget -O kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectl
$ kubectl version --client --short
Client Version: v1.10.3
Також існують репозиторії kubectl для Debian/RedHat-подібних ОС, MacOS і навіть Windows.
2. SETUP YOUR ENVIRONMENT
Для установки Kubernetes kops потребує окремого користувача, якого необхідно наділити наступними IAM правами:
AmazonEC2FullAccess
AmazonRoute53FullAccess
AmazonS3FullAccess
IAMFullAccess
AmazonVPCFullAccess
Створимо такого користувача, використавши вже налаштований awscli клієнт. Спочатку створимо групу kops, до якої додамо всі згадані вище права:
$ aws iam create-group --group-name kops
$ aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess \
--group-name kops
$ aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonRoute53FullAccess \
--group-name kops
$ aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess \
--group-name kops
$ aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/IAMFullAccess \
--group-name kops
$ aws iam attach-group-policy \
--policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess \
--group-name kops
І вже потім створимо аналогічного користувача та додамо його в цю щойно створену групу:
$ aws iam create-user --user-name kops
$ aws iam add-user-to-group --user-name kops --group-name kops
Результатом наступної команди буде ключ користувача kops:
$ aws iam create-access-key --user-name kops
Виходячи із значень SecretAccessKey та AccessKeyID нового користувача переналаштуємо awscli:
$ aws configure
AWS Access Key ID [****************EYID]: NEWKOPSKEYID
AWS Secret Access Key [****************ALUE]: NEWKOPSKEYSECRET
Default region name [us-east-1]:
Default output format [None]:
Перевіримо чи справді він був створений та чи коректно працює клієнт з новим обліковим записом:
$ aws iam list-users
{
"Users": [
{
...
},
{
"Path": "/",
"UserName": "kops",
"UserId": "NEWKOPSKEYID",
"Arn": "arn:aws:iam::123456789:user/kops",
"CreateDate": "2018-05-22T16:26:12Z"
}
]
}
Експортуємо значення ключа до змінних середовища, адже kops не вміє читати їх самостійно:
$ export AWS_ACCESS_KEY_ID=$(aws configure get aws_access_key_id)
$ export AWS_SECRET_ACCESS_KEY=$(aws configure get aws_secret_access_key)
3. DNS
Ми будемо використовувати внутрішню DNS-зону AWS local.(gossip based cluster), але є і інші варіанти, серед яких:
- Купити окремий домен в AWS Route 53, який надалі буде використовуватись для установки Kubernetes. Найбільш простий, але і найбільш затратний по вартості варіант. Якщо, наприклад, буде куплено домен example.com, то доменне ім'я вузлу etcd матиме вигляд etcd-us-east-1c.internal.clustername.example.com
- Використовувати для вузлів кластеру піддомен, що куплений/хоститься в AWS Route 53. З деталями можна ознайомитись за посиланням.
- Перенести домен, що був куплений в іншого реєстратора, до AWS Route 53. Після міграції вже можна його використовувати повністю чи створити окремий піддомен для інсталяції (див. попередні пункти). Як це зробити детально можна прочитати тут.
- Перенести до Route 53 лише піддомен і залишити оригінальний домен в реєстратора. Зручно, якщо немає бажання платити зайві кошти за обслуговування нового домену. Новий піддомен необхідно створити у власного реєстратора та перенести його NS-записи до AWS.
Як я вже згадував, ми скористаємось внутрішньої AWS dns-зоною і створювати наразі окремий домен немає необхідності. Бажання, що саме її ми хочемо використовувати, kops зрозуміє по змінній KOPS_NAME, що має закінчуватись на k8s.local:
$ export KOPS_NAME=ipeacocks.k8s.local
4. CLUSTER STATE STORAGE (AWS S3 BUCKET)
Для збереження свого стану (і кластеру) kops зберігає дані налаштувань в окремому AWS S3 bucket. Створимо новий бакет та одразу активуємо версійність на ньому:
$ aws s3api create-bucket \
--bucket ipeacocks-kops \
--region us-east-1
Для відмінних від us-east-1 регіонів необхідно також додавати ключ '--create-bucket-configuration LocationConstraint=region-name'
$ aws s3api put-bucket-versioning \
--bucket ipeacocks-kops \
--versioning-configuration Status=Enabled
Версійність не обов'язкова, але не буде зайвою у випадку повернення до минулого стану конфігураційних файлів кластеру. Ім’я бакету має бути унікальним в межах одного регіону, тож можливо його необхідно буде змінити.
Окрім цього kops вміє працювати з зашифрованими бакетами. Експортуємо ще одну змінну середовища для kops:
$ export KOPS_STATE_STORE=s3://ipeacocks-kops
5. KUBERNETES CLUSTER INSTALLATION
Далі ми розглянемо варіант установки кластеру із застосування Terraform та без. У будь-якому випадку Kops вважатиме конфігураційні файли стану (що зберігатимуться в окремому S3 bucket) остаточним і кінцевим джерелом істини.
У обох варіантах ми будемо інсталювати K8s в окремий VPS із приватними підмережами.
5.1. Setup Cluster W/O Terraform
Наразі нам нічого не заважає перейти до створення кластеру. Отже виконуємо наступне:
$ kops create cluster ${KOPS_NAME} \
--state ${KOPS_STATE_STORE} \
--node-count 3 \
--master-count 3 \
--zones us-east-1a,us-east-1b,us-east-1c \
--master-zones us-east-1a,us-east-1b,us-east-1c \
--cloud aws \
--node-size t2.medium \
--master-size t2.medium \
--topology private \
--ssh-public-key="~/.ssh/id_rsa.pub" \
--networking flannel \
--image ami-a4dc46db
...
Must specify --yes to apply changes
Cluster configuration has been created.
Suggestions:
* list clusters with: kops get cluster
* edit this cluster with: kops edit cluster ipeacocks.k8s.local
* edit your node instance group: kops edit ig --name=ipeacocks.k8s.local nodes
* edit your master instance group: kops edit ig --name=ipeacocks.k8s.local master-us-east-1a
Finally configure your cluster with: kops update cluster ipeacocks.k8s.local --yes
Команда вище створить конфігурацію із 3 вузлів в якості воркерів (нод) та стільки ж майстрів. На цих майстрах будуть встановлені бази etcd, саме тому їхня кількість обрана непарною (питання кворуму і т.п.).
Воркери і майстри будуть лежати в різних зонах доступності AWS (Availability Zone, AZ). Теоретично окремі з них можуть падати (хоча у своєму досвіді я такого не зустрічав) і таким чином кластер все ж залишатиметься робочим. Проте мінусом даного варіанту буде те, що таким чином інфраструктура ускладниться і стане дорожчою (необхідно буде 3 NAT Gateway, по одному в кожній AZ, вартість кожного із яких біля $40 на місяць + трафік). Деякі регіони AWS можуть мати менше зон доступності, переглянути їх всі можна виконавши:
$ aws ec2 describe-availability-zones --region us-east-1
Щоб розмістити вузли лише в одній зоні необхідно вказати до ключа --zones лише одну зону, наприклад --zones us-east-1a, а аргумент --master-zones можна прибрати повністю. У такому разі всі EC2-інстанси будуть знаходитись лише в одній AZ.
У якості EC2-інстансів для воркерів та майстрів я обрав t2.medium, навіть для тестових цілей не варто розглядати менш потужні інстанси. Тип EC2 зручно підбирати за наступним посиланням https://www.ec2instances.info.
Завдяки опції --topology private kops власноруч побудує приватну мережу в окремому VPC і створить підмережі (subnets) для воркерів та майстрів в кожній зоні доступності. Кожен вузол буде мати доступ до мережі Інтернет завдяки NAT Gateway, котрий буде додано до кожної приватної підмережі. Без ключа --topology, kops побудує публічну мережу і розмістить у ній всі вузли.
За допомогою ключів --vpc та --subnets кластер можна встановити у VPC та підмережах відповідно, що вже були створені. Як правило, kops по-замовчуванню створює дійсно великі підмережі, що може бути не бажано.
У випадку приватної підмережі одразу можна вказувати ключ --bastion, що відповідає за створення bastion хосту з якого відкривається ssh-доступ до всього кластеру. Проте через існування багу це ще зробити поки неможливо і bastion вже буде додано власноруч після створення K8s кластеру. У випадку з використанням власного домену (див. секцію DNS) ця проблема відсутня.
У якості CNI networking plugin я обрав flannel, але за необхідності можна обрати щось інше. У якості ОС для вузлів буде використовуватись Ubuntu, останній AMI image якої можна знайти за посиланням https://cloud-images.ubuntu.com/locator (імена образів різняться в залежності від регіону). У якості образу по замовчуванню у проекті Kops виступає Debian 9 із спеціальним ядром оптимізованим для Kubernetes вузлів, котрий обирається по замовчуванню, якщо інший образ не буде вказаний прямо. Інші операційні системи також доступні, часом з певними застереженнями.
Усіх опцій kops дуже забагато, для ознайомлень з ними краще запустити kops <your_action> -h. Наприклад, список всіх актуальних опцій для створення кластеру можна отримати так:
$ kops create cluster -h
Сама установка починається лише після передачі аргументу --yes:
$ kops update cluster ${KOPS_NAME} --yes
...
Cluster is starting. It should be ready in a few minutes.
Suggestions:
* validate cluster: kops validate cluster
* list nodes: kubectl get nodes --show-labels
* ssh to the master: ssh -i ~/.ssh/id_rsa admin@api.ipeacocks.k8s.local
* the admin user is specific to Debian. If not using Debian please use the appropriate user based on your OS.
* read about installing addons at: https://github.com/kubernetes/kops/blob/master/docs/addons.md.
Цей же ключ може бути переданий одразу на етапі створення конфігурації кластеру і установка почнеться одразу. Через 15-20 хвилин кластер буде повністю встановлено, за його статусом можна спостерігати командою validate:
$ kops validate cluster
Using cluster from kubectl context: ipeacocks.k8s.local
Validating cluster ipeacocks.k8s.local
INSTANCE GROUPS
NAME ROLE MACHINETYPE MIN MAX SUBNETS
master-us-east-1a Master t2.medium 1 1 us-east-1a
master-us-east-1b Master t2.medium 1 1 us-east-1b
master-us-east-1c Master t2.medium 1 1 us-east-1c
nodes Node t2.medium 3 3 us-east-1a,us-east-1b,us-east-1c
NODE STATUS
NAME ROLE READY
ip-172-20-122-135.ec2.internal node True
ip-172-20-127-138.ec2.internal master True
ip-172-20-38-131.ec2.internal node True
ip-172-20-63-161.ec2.internal master True
ip-172-20-81-46.ec2.internal node True
ip-172-20-85-15.ec2.internal master True
Your cluster ipeacocks.k8s.local is ready
Під час створення кластеру kops скопіює конфігураційний файл необхідний для роботи kubectl до директорії ~/.kube, тож ми одразу зможемо працювати з кластером:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-20-122-135.ec2.internal Ready node 1m v1.9.6
ip-172-20-127-138.ec2.internal Ready master 2m v1.9.6
ip-172-20-38-131.ec2.internal Ready node 1m v1.9.6
ip-172-20-63-161.ec2.internal Ready master 2m v1.9.6
ip-172-20-81-46.ec2.internal Ready node 1m v1.9.6
ip-172-20-85-15.ec2.internal Ready master 2m v1.9.6
Для роботи з декількома кластерами одночасно дуже рекомендую утиліти kubectx/kubens, вони будуть корисним доповненням до стандартного функціоналу kubectl.
Лишилось додати bastion (ssh) хост до інфраструктури. Це досить не складно:
$ kops create instancegroup bastions --role Bastion --subnet utility-us-east-1a --name ${KOPS_NAME}
Команда додасть опис нової групи інстансів (instance group) bastions в підмережі utility-us-east-1a, що вже була створена kops-ом і відкриє редактор на перегляд відповідного yaml-файлу:
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: null
name: bastions
spec:
image: ami-a4dc46db
machineType: t2.micro
maxSize: 1
minSize: 1
role: Bastion
subnets:
- utility-us-east-1a
У ньому ми змінили ім'я AMI образу на Ubuntu 16.04 з останніми оновленнями. Бастіон вузли будуть знаходитись в публічній мережі з балансувальником попереду. Наразі ми плануємо додати лише один хост, проте їхню кількість можна збільшити до, наприклад, 2-ох і таким чином збільшити рівень доступності під однією точкою входу. Для цього потрібно відредагувати параметри minSize та maxSize. Якщо ж разом з тим ще й додати підмережі в інших AZ (utility-us-east-1b та utility-us-east-1c уже створені), то нові вузли bastion будуть рознесені по цим AZ.
Група інстансів (instance group) - це група, подібних за виконуваними функціями, серверів, що можуть лінійно масштабуватись. Отримати перелік усіх доступних груп, кількості вузлів у них та в яких зонах вони знаходяться можна виконавши команду:
$ kops get instancegroups
Using cluster from kubectl context: ipeacocks.k8s.local
NAME ROLE MACHINETYPE MIN MAX ZONES
bastions Bastion t2.micro 1 1 us-east-1a
master-us-east-1a Master t2.medium 1 1 us-east-1a
master-us-east-1b Master t2.medium 1 1 us-east-1b
master-us-east-1c Master t2.medium 1 1 us-east-1c
nodes Node t2.medium 3 3 us-east-1a,us-east-1b,us-east-1c
Наразі для появи bastion-у необхідно запустити оновлення кластеру через kops:
$ kops update cluster ${KOPS_NAME} --yes
Щоб не шукати ім'я балансувальника в консолі AWS, виконаємо API-запит:
$ aws elb --output=table describe-load-balancers | grep DNSName.\*bastion | awk '{print $4}'
bastion-ipeacocks-k8s-loc-o6gusl-1428745349.us-east-1.elb.amazonaws.com
Підключаємось до bastion з приватним ssh-ключем, публічну частину якого завантажили раніше під час створення кластеру:
$ ssh ubuntu@bastion-ipeacocks-k8s-loc-o6gusl-1428745349.us-east-1.elb.amazonaws.com -i ~/.ssh/id_rsa
Доменне ім'я балансувальника може бути доступним не одразу, в залежності від швидкості оновлення записів на DNS-серверах.
5.2. Setup Cluster With Terraform
Kops здатний генерувати Terraform конфігурацію і вже потім останній може її застосовувати. Це може бути зручно, якщо Terraform вже використовується для опису інфраструктури чи для стеження за змінами конфігурації кластеру (звісно у випадках використання систем керування версіями).
Хоч це вже трохи інша розмова, проте дуже бажано зберігати стани Terraform (state) в окремому S3 бакеті. Таким чином команда, в якій ви працюєте, зможе запобігти багатьом конфліктам при обслуговуванні інфраструктури. Це справді дуже серйозно і не варто цим нехтувати. Отож створимо новий bucket і увімкнемо версійність для нього:
$ aws s3api create-bucket \
--bucket ipeacocks-tf-state \
--region us-east-1
$ aws s3api put-bucket-versioning \
--bucket ipeacocks-tf-state \
--versioning-configuration Status=Enabled
Тепер створимо необхідну директорію, в котрій зберігатиметься Terraform конфігурація, та додамо інформацію, що tfstate буде зберігатись віддалено, в щойно створеному bucket:
$ mkdir ipeacocks-k8s
$ cd ipeacocks-k8s
$ vim aws.tf
terraform {
backend "s3" {
bucket = "ipeacocks-tf-state"
key = "ipeacocks-k8s.tfstate"
region = "us-east-1"
}
}
Ще ліпше користуватись DynamoDB lock-ами, щоб уникнути можливості одночасного запуску Terraform-у.
Для застосування цих змін необхідно установити Terraform та виконати наступне:
$ terraform init
Після чого можна запустити генерацію конфігурації майбутнього кластера:
$ kops create cluster ${KOPS_NAME} \
--state ${KOPS_STATE_STORE} \
--node-count 3 \
--master-count 3 \
--zones us-east-1a,us-east-1b,us-east-1c \
--master-zones us-east-1a,us-east-1b,us-east-1c \
--cloud aws \
--node-size t2.medium \
--master-size t2.medium \
--topology private \
--ssh-public-key="~/.ssh/id_rsa.pub" \
--networking flannel \
--image ami-a4dc46db \
--out=. \
--target=terraform
...
Terraform output has been placed into .
Run these commands to apply the configuration:
cd .
terraform plan
terraform apply
Suggestions:
* validate cluster: kops validate cluster
* list nodes: kubectl get nodes --show-labels
* ssh to the master: ssh -i ~/.ssh/id_rsa admin@api.ipeacocks.k8s.local
* the admin user is specific to Debian. If not using Debian please use the appropriate user based on your OS.
* read about installing addons at: https://github.com/kubernetes/kops/blob/master/docs/addons.md.
У результаті в поточній директорії з'явиться файл kubernetes.tf та директорія data, в котрій знаходяться launch конфігурації для autoscaling груп, публічний ключ (котрий був вказаний аргументом kops-у) та інше:
$ tree .
.
├── aws.tf
├── data
│ ├── aws_iam_role_masters.ipeacocks.k8s.local_policy
│ ├── aws_iam_role_nodes.ipeacocks.k8s.local_policy
│ ├── aws_iam_role_policy_masters.ipeacocks.k8s.local_policy
│ ├── aws_iam_role_policy_nodes.ipeacocks.k8s.local_policy
│ ├── aws_key_pair_kubernetes.ipeacocks.k8s.local-b3b3005f1f991b3e9b0bd39130e6410a_public_key
│ ├── aws_launch_configuration_master-us-east-1a.masters.ipeacocks.k8s.local_user_data
│ ├── aws_launch_configuration_master-us-east-1b.masters.ipeacocks.k8s.local_user_data
│ ├── aws_launch_configuration_master-us-east-1c.masters.ipeacocks.k8s.local_user_data
│ └── aws_launch_configuration_nodes.ipeacocks.k8s.local_user_data
└── kubernetes.tf
За втілення планів у життя тепер вже буде відповідати Terraform:
$ terraform plan
$ terraform apply
...
Apply complete! Resources: 72 added, 0 changed, 0 destroyed.
Outputs:
cluster_name = ipeacocks.k8s.local
master_security_group_ids = [
sg-ef73dda4
]
masters_role_arn = arn:aws:iam::789248082627:role/masters.ipeacocks.k8s.local
masters_role_name = masters.ipeacocks.k8s.local
node_security_group_ids = [
sg-5372dc18
]
node_subnet_ids = [
subnet-602bf43c,
subnet-ff7da398,
subnet-9f4099b1
]
nodes_role_arn = arn:aws:iam::789248082627:role/nodes.ipeacocks.k8s.local
nodes_role_name = nodes.ipeacocks.k8s.local
region = us-east-1
vpc_id = vpc-6b658011
Через 15-20 хв кластер має бути готовим. Окрім проблеми зі створенням bastion-у додалась ще і нова. Тобто після створення кластеру через Terraform, буде додано не вірний api-сервер до ~/.kube/config. І навіть після його ручного редагування це не змінить ситуацію, адже сертифікат на API-серверах виписано без урахування коректного імені. Це стосується лише gossip-based режиму (використання внутрішньої DNS-зони AWS). Але є workaround і для цього необхідно пройти наступну процедуру:
$ kops update cluster ${KOPS_NAME} --out=. --target=terraform
$ terraform apply
$ kops export kubecfg ${KOPS_NAME}
kops has set your kubectl context to ipeacocks.k8s.local
$ kops rolling-update cluster --cloudonly --force --yes
Using cluster from kubectl context: ipeacocks.k8s.local
NAME STATUS NEEDUPDATE READY MIN MAX
master-us-east-1a Ready 0 1 1 1
master-us-east-1b Ready 0 1 1 1
master-us-east-1c Ready 0 1 1 1
nodes Ready 0 3 3 3
...
W0619 00:10:16.214647 20947 instancegroups.go:152] Not draining cluster nodes as 'cloudonly' flag is set.
I0619 00:10:16.214656 20947 instancegroups.go:275] Stopping instance "i-0e679777920304017", in group "nodes.ipeacocks.k8s.local".
W0619 00:14:17.161002 20947 instancegroups.go:184] Not validating cluster as cloudonly flag is set.
I0619 00:14:17.161282 20947 rollingupdate.go:193] Rolling update completed for cluster "ipeacocks.k8s.local"!
Ці kops команди згенерують новий сертифікат, враховуючи ім'я балансувальника попереду K8s майстрів, змінять локальний ~/.kube/config, додавши до його конфігурації вірну адресу API-сервера (адресу зовнішнього балансувальника) та завантажить новий коректний сертифікат на всі вузли. Це займе пристойну кількість часу, зазвичай 20-30 хв. Після цього вже можна буде переглянути статус кластера і переконатись у його коректній роботі:
$ kops validate cluster
Using cluster from kubectl context: ipeacocks.k8s.local
Validating cluster ipeacocks.k8s.local
INSTANCE GROUPS
NAME ROLE MACHINETYPE MIN MAX SUBNETS
master-us-east-1a Master t2.medium 1 1 us-east-1a
master-us-east-1b Master t2.medium 1 1 us-east-1b
master-us-east-1c Master t2.medium 1 1 us-east-1c
nodes Node t2.medium 3 3 us-east-1a,us-east-1b,us-east-1c
NODE STATUS
NAME ROLE READY
ip-172-20-125-62.ec2.internal node True
ip-172-20-126-59.ec2.internal master True
ip-172-20-46-76.ec2.internal master True
ip-172-20-59-65.ec2.internal node True
ip-172-20-84-105.ec2.internal node True
ip-172-20-84-26.ec2.internal master True
Your cluster ipeacocks.k8s.local is ready
Bastion додається майже аналогічно, окрім того, що тепер зміни мають застосовуватись Teraform-ом:
$ kops create instancegroup bastions --role Bastion --subnet utility-us-east-1a --name ${KOPS_NAME}
У вікні редактора змінюємо тип AMI:
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: null
name: bastions
spec:
image: ami-a4dc46db
machineType: t2.micro
maxSize: 1
minSize: 1
role: Bastion
subnets:
- utility-eu-central-1a
Генеруємо оновлення Terraform конфігурації та застосовуємо її:
$ kops update cluster ${KOPS_NAME} --out=. --target=terraform
$ terraform plan
$ terraform apply
...
Apply complete! Resources: 15 added, 0 changed, 2 destroyed.
Outputs:
bastion_security_group_ids = [
sg-27359b6c
]
bastions_role_arn = arn:aws:iam::789248082627:role/bastions.ipeacocks.k8s.local
bastions_role_name = bastions.ipeacocks.k8s.local
cluster_name = ipeacocks.k8s.local
master_security_group_ids = [
sg-ef73dda4
]
masters_role_arn = arn:aws:iam::789248082627:role/masters.ipeacocks.k8s.local
masters_role_name = masters.ipeacocks.k8s.local
node_security_group_ids = [
sg-5372dc18
]
node_subnet_ids = [
subnet-602bf43c,
subnet-ff7da398,
subnet-9f4099b1
]
nodes_role_arn = arn:aws:iam::789248082627:role/nodes.ipeacocks.k8s.local
nodes_role_name = nodes.ipeacocks.k8s.local
region = us-east-1
vpc_id = vpc-6b658011
Для SSH-підключення необхідно використовувати адресу ELB попереду bastion-хосту, тому дізнаємось її, виконавши наступне:
$ aws elb --output=table describe-load-balancers | grep DNSName.\*bastion | awk '{print $4}'
bastion-ipeacocks-k8s-loc-o6gusl-2141452173.us-east-1.elb.amazonaws.com
Та підключемось до нього:
$ ssh ubuntu@bastion-ipeacocks-k8s-loc-o6gusl-2141452173.us-east-1.elb.amazonaws.com -i ~/.ssh/id_rsa
Для того щоб не було необхідності тримати приватні ssh-ключі на бастіоні, ключі мають бути додані до ssh-agent-у та в .ssh/config має бути дозволено пересилка приватного ключа. Щось на зразок цього:
$ cat ~/.ssh/config
Host *
ForwardAgent yes
Будь-які зміни конфігурації вже інстальованого таким чином кластера мають відбуватись із залученням Terraform. Для прикладу так проходить зміна типу інстансу для воркерів:
$ kops edit ig nodes
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: 2018-06-18T20:05:49Z
labels:
kops.k8s.io/cluster: ipeacocks.k8s.local
name: nodes
spec:
image: ami-a4dc46db
machineType: t2.large
maxSize: 3
minSize: 3
nodeLabels:
kops.k8s.io/instancegroup: nodes
role: Node
subnets:
- us-east-1a
- us-east-1b
- us-east-1c
Тобто було відредаговано групу інстансів nodes та виставлено новий тип EC2 (machineType: t2.large). Аналогічно, тут можна змінити підмережі, кількість вузлів для воркерів і т.п. Далі потрібно згенерувати нову terraform конфігурацію і застосувати її:
$ kops update cluster ${KOPS_NAME} --out=. --target=terraform
$ terraform plan
$ terraform apply
Проте це ще не все. З новим типом інстансу будуть стартувати лише нові воркери. Нова конфігурація на вже створені вузли буде застосована лише у разі запуску rolling-update:
$ kops rolling-update cluster --yes
Тепер kops по черзі буде зупиняти вузли воркерів кластеру і замінювати їх на t2.large. Зазвичай rolling-update необхідний лише у разі зміни характеристик вузлів, що вже працюють (диск, тип інстансів, AMI), і не потрібний, наприклад, у разі масштабування кількості одиниць груп інстансів.
5.3. Share Access with Your DevOps Team
Для того, щоб поділитись доступом до кластеру (API K8s) варто лише передати AWS API Key користувача kops:
$ export AWS_ACCESS_KEY_ID=NEWKOPSKEYID
$ export AWS_SECRET_ACCESS_KEY=NEWKOPSKEYSECRET
Ім'я кластера та адресу S3 відра:
$ export KOPS_NAME=ipeacocks.k8s.local
$ export KOPS_STATE_STORE=s3://ipeacocks-kops
Цього буде досить для завантаження конфігураційного файлу ~/.kube/config для роботи kubectl та kops:
$ kops export kubecfg ${KOPS_NAME}
$ kubectl get nodes
$ kops validate cluster
6. KOPS AWS INFRASTRUCTURE SCHEME
Окремим пунктом хотілося б проілюструвати як саме kops підготував інфраструктуру для установки Kubernetes. Нагадаю, що за допомогою ключа '--topology private' ми розмістили поза NAT-ом всі вузли Kubernetes. Якщо говорити конкретніше, то kops створив окремий VPC:

І додав DHCP сервер до нього:

У цьому VPC було створено 6 підмереж: 3 публічних (utility-us-east-1*) в трьох різних AZ та 3 приватних (us-east-1*) також в окремій зоні доступності кожна.
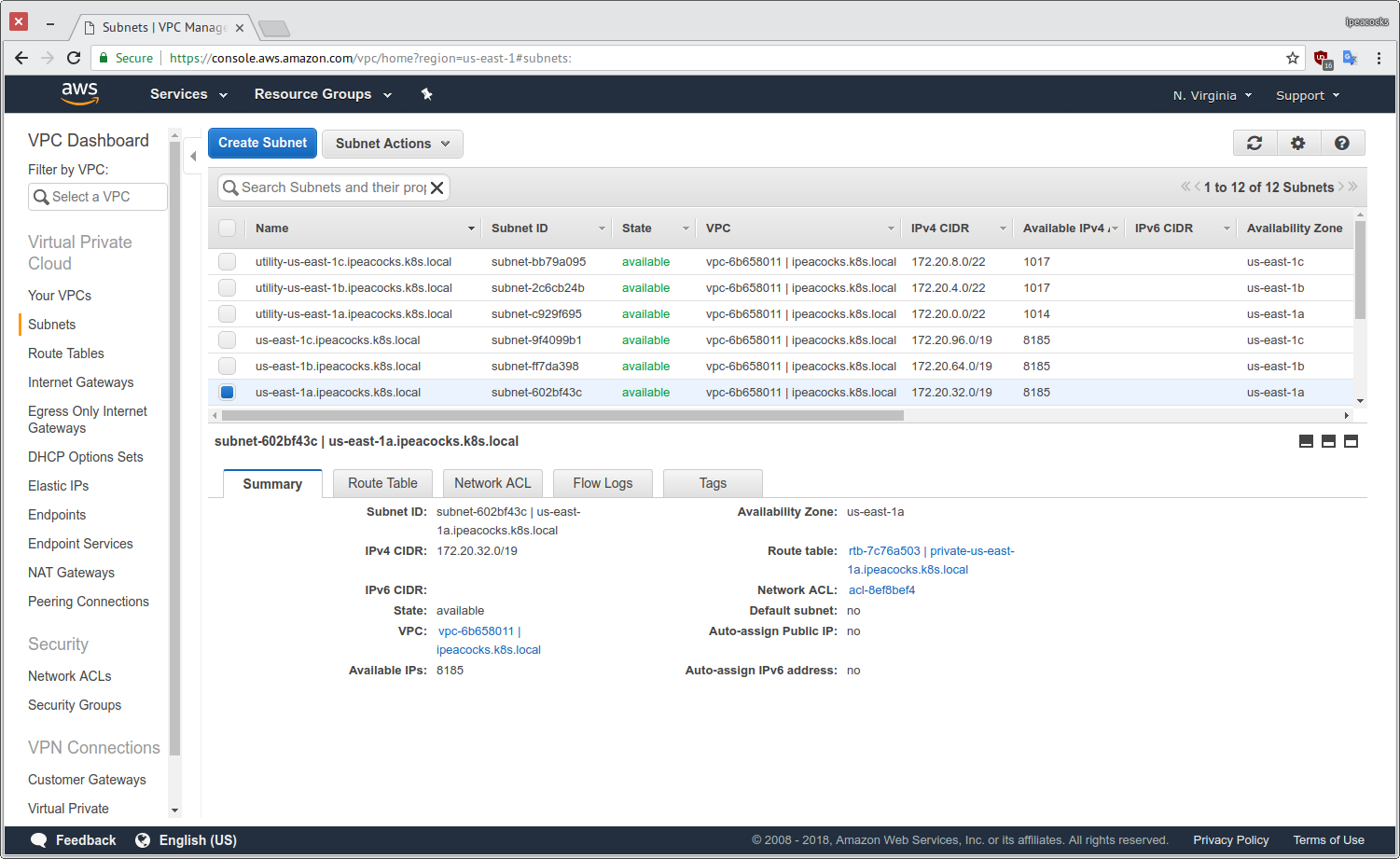
Для доступу до мережі інтернет до VPC додано Internet Gateway:

Для приватних мереж було додано 3 NAT Gateway, тобто по гейтвею на одну приватну мережу в кожному AZ:

Ці гейтвеї лежать у публічних мережах (utility-us-east-1*), адже їм необхідні постійні публічні IP адреси (EIP) і очевидно доступ до мережі Інтернет:

Зовнішній трафік публічних мереж (utility-us-east-1*) маршрутизується одразу на Internet Gateway, тому вони власне і називаються публічними:


Трафік приватних мереж потрапляє на NAT гейтвеї кожної із AZ мереж (a, b, c):


Як і було вказано аргументом до kops було створено 3 воркера (по одному в кожній приватній підмережі us-east-1* кожної зони доступності), 3 майстра Kubernetes (аналогічне розміщення з воркерами) та один бастіон хост (розміщується в публічній підмережі utility-us-east-1a):

До вузлів підключені наступні диски (EBS):

Перше, що не дуже зрозуміло, це навіщо за замовчуванням bastion-хосту виділяється аж 32ГБ SSD пам'яті? Проте цей розмір можна з легкістю зменшити як після генерації конфігурації кластеру, так і під час його роботи. Дані etcd розділено на два кластери: events та main і вони фізично розміщені на майстрах.
Майстри Kubernetes знаходяться за балансувальником api-ipeacocks-k8s-local-*. Він використовується як єдина точка з’єднань для воркерів: після додавання нових майстрів не потрібно буде жодним чином змінювати конфігурацію воркерів. У цьому можна пересвідчитись переглянувши конфігураційний файл /var/lib/kube-proxy/kubeconfig. Варто зауважити, що цей балансувальник зовнішній, тобто його видно з мережі Інтернет. Він використовується також як інтерфейс API до кластера і kubectl працює саме з ним. За необхідності його можна зробити приватним (під генерації конфігурації kops-ом, передавши аргумент --api-loadbalancer-type internal чи після), після чого управляти ним через kubectl необхідно буде з bastion-у.
Bastion вузол аналогічно знаходиться за балансувальником, котрий перенаправляє запити на 22 порт відповідних EC2 вузлів. І саме по цій причині його можна масштабувати по різних підмережах різних зон доступності.

Кожна група вузлів має досить чіткі обмеження на підключення (inbound/outbound rules). Наприклад майстри дозволяють ssh-підключення тільки з бастіонів (тобто security group бастіонів), на доступ з воркерів відкриті порти починаючи з 4003 і т.п:

Групи вузлів (майстри, воркери, бастіони) знаходяться в Auto Scalling Groups (ASG) з відповідним для кожної групи Launch Configuration:

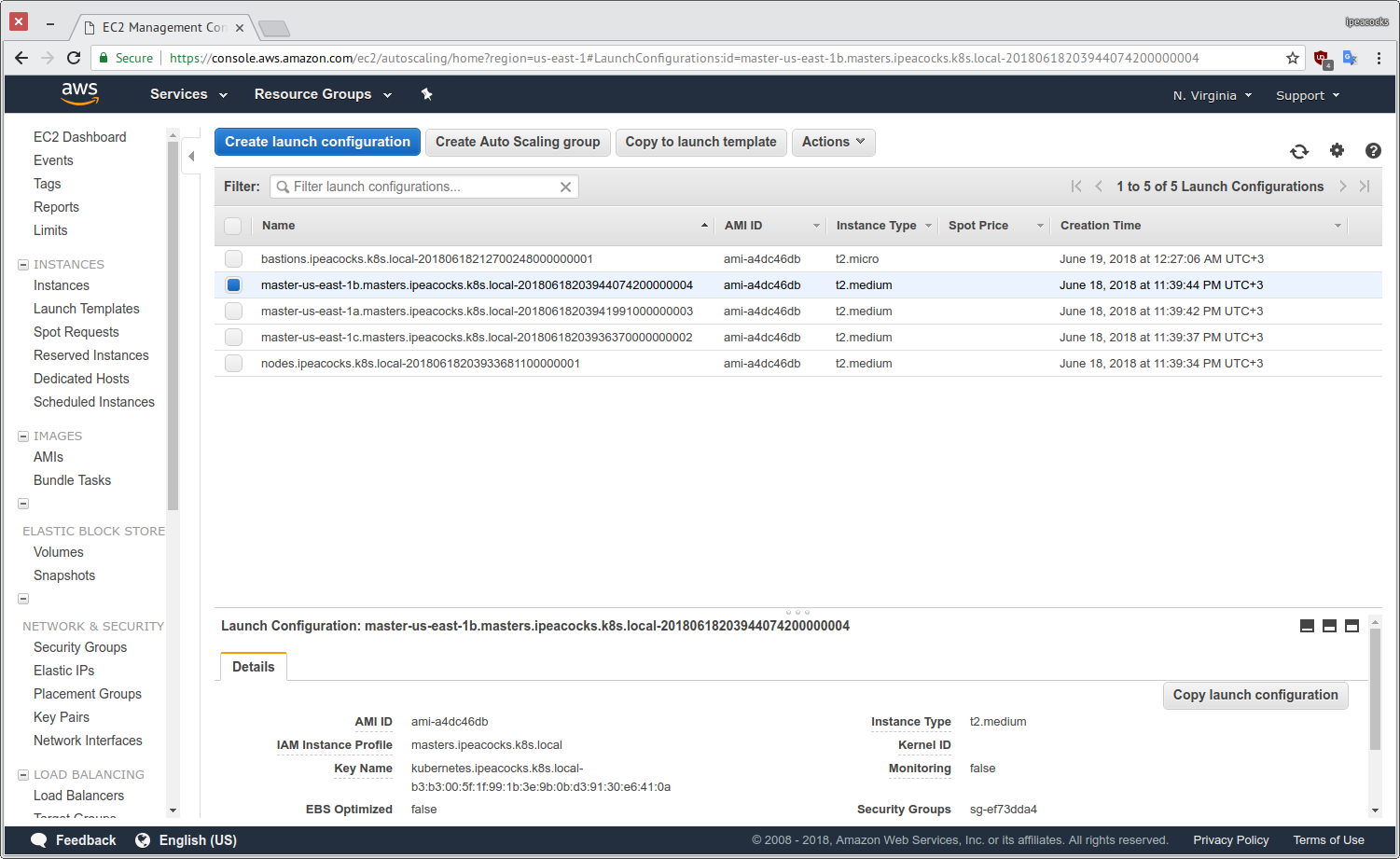

У випадку, якщо якийсь вузол перестане працювати - ASG, виходячи з опису LC, до якої саме групи відноситься вузол, підніме аналогічний. Більш того, за можливості буде підключено ELB-диск даних попереднього інстансу (проте, здається, це стосується лише майстрів однієї AZ). Диски не можуть мігрувати між різними зонами доступності.
Зібравши цю інформацію докупи, можна уявити приблизно таку схему:

7. KUBERNETES / KOPS ADDONS
У цьому розділі я розповім про те, які додатки офіційно підтримує проект kops і з якими маю хоча б невеликий досвід. Власне вони можуть бути дещо видозмінені за оригінальні для кращої інтеграції в системи AWS. З усіма додатками, які підтримує проект Kops можна ознайомитись за наступним посиланням https://github.com/kubernetes/kops/tree/master/addons
7.1. Ingress
Ingress - це ресурс кластеру Kubernetes, додатковий об’єкт, що вирішує проблему адресації трафіку на поди в залежності від імені віртуального хосту, на який відправляється запит. Я вже писав досить обширну статтю щодо того, як встановити і зконфігурувати Ingress на bare-metal інсталяціях, цього ж разу піде мова щодо роботи Ingress в AWS середовищі.
Як і для попередніх аддонів, для установки скористаємось описом Ingress контролера, що зберігається в kops репозиторію:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/ingress-nginx/v1.6.0.yaml
namespace "kube-ingress" created
serviceaccount "nginx-ingress-controller" created
clusterrole.rbac.authorization.k8s.io "nginx-ingress-controller" created
role.rbac.authorization.k8s.io "nginx-ingress-controller" created
clusterrolebinding.rbac.authorization.k8s.io "nginx-ingress-controller" created
rolebinding.rbac.authorization.k8s.io "nginx-ingress-controller" created
service "nginx-default-backend" created
deployment.extensions "nginx-default-backend" created
configmap "ingress-nginx" created
service "ingress-nginx" created
deployment.extensions "ingress-nginx" created
У результаті чого буде створено новий ELB з переадресацією трафіку зі стандартних HTTP/HTTPS портів (вони будуть прослуховуватись на самому балансувальнику) на 32743/32232 (адреси новоствореного Ingress контролера всередині Kubernetes інсталяції) відповідно:
$ kubectl get service ingress-nginx -n kube-ingress
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 100.68.73.68 a9b83f4blabla... 80:31999/TCP,443:32202/TCP 2m
Под контролера буде запущено на кожному воркері, тобто у нашому випадку їх буде 3.
Для перевірки коректності роботи Ingress запустимо простий додаток echoheaders (деплоймент, якщо точніше), що просто буде виводити хедери запитів:
$ kubectl run echoheaders --image=k8s.gcr.io/echoserver:1.4 --replicas=1 --port=8080
Створимо сервіс для нього:
$ kubectl expose deployment echoheaders --port=80 --target-port=8080 --name=echoheaders-x
Перевіримо чи вони вже справді працюють:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
echoheaders-x ClusterIP 100.67.148.219 <none> 80/TCP 33s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
echoheaders-775d56877d-kkdvf 1/1 Running 0 25s
$ kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
echoheaders 1 1 1 1 2m
Опишемо Ingress для нового сервісу echoheaders-x та застосуємо його:
$ vim ingress-echoheaders-x.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: echomap
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: echoheaders-x
servicePort: 80
$ kubectl apply -f ingress-echoheaders-x.yaml
ingress.extensions "echomap" created
$ kubectl get ing
NAME HOSTS ADDRESS PORTS AGE
echomap foo.bar.com 80 27s
Дещо більш комплексний варіант можна знайти тут https://raw.githubusercontent.com/kubernetes/contrib/master/ingress/controllers/nginx/examples/ingress.yaml
Перевіримо чи Ingress справді працює, відправивши в запиті ім'я хосту, котрий був описаний вище:
$ curl -H "Host: foo.bar.com" http://a9b83f4f1773c11e8b2060e6e89642d8-1717448270.us-east-1.elb.amazonaws.com/foo
CLIENT VALUES:
client_address=100.67.148.219
command=GET
real path=/foo
query=nil
request_version=1.1
request_uri=http://foo.bar.com:8080/foo
SERVER VALUES:
server_version=nginx: 1.10.0 - lua: 10001
HEADERS RECEIVED:
accept=*/*
connection=close
host=foo.bar.com
user-agent=curl/7.55.1
x-forwarded-for=78.28.194.166
x-forwarded-host=foo.bar.com
x-forwarded-port=80
x-forwarded-proto=http
x-original-uri=/foo
x-real-ip=78.28.194.166
x-scheme=http
BODY:
-no body in request-%
https://github.com/kubernetes/ingress-nginx/
https://kubernetes.github.io/ingress-nginx/how-it-works/
https://github.com/kubernetes/ingress-nginx/tree/master/docs/examples
https://github.com/kubernetes/contrib/tree/master/ingress/controllers/nginx/examples
https://itnext.io/save-on-your-aws-bill-with-kubernetes-ingress-148214a79dcb
7.2. Kubernetes Dashboard
Dashboard - web-панель для Kubernetes, що дозволяє користувачам керувати самим кластером та управляти додатками, що працюють в ньому. Це мабуть найбільш популярний і необхідний додаток для Kubernetes, особливо якщо "не клеїться" з консольним клієнтом kubectl. Скористуємось маніфестом для установки з репозиторію kops:
$ kubectl create -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/kubernetes-dashboard/v1.8.3.yaml
secret "kubernetes-dashboard-certs" created
serviceaccount "kubernetes-dashboard" created
role.rbac.authorization.k8s.io "kubernetes-dashboard-minimal" created
rolebinding.rbac.authorization.k8s.io "kubernetes-dashboard-minimal" created
deployment.apps "kubernetes-dashboard" created
service "kubernetes-dashboard" created
У kops доступ до K8s Dashboard реалізований з API серверів, хоча ніхто не забороняє надалі його опублікувати через Ingress, виділивши окремий домен. Так як API (майстри) знаходяться поза балансувальником - то спочатку потрібно дізнатись саме його адресу:
$ aws elb --output=table describe-load-balancers | grep DNSName.\*bastion | awk '{print $4}'
api-ipeacocks-k8s-local-20s66v-1218352498.us-east-1.elb.amazonaws.com
Дані до basic auth наступні:
* Логін: admin
* Для отримання паролю необхідно виконати kops get secrets kube --type secret -oplaintext чи kubectl config view --minify
Пароль у нашому випадку буде таким:
$ kops get secrets kube --type secret -oplaintext
Using cluster from kubectl context: ipeacocks.k8s.local
pk4TSVqZYgf5ZJ3u8A4E3jbDsPZWSvvd
Так як панель вже захищена паролем, відімкнемо додатковий захист по Bearer Token :
$ vim dashboard_clusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
labels:
k8s-app: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
$ kubectl apply -f dashboard_clusterrole.yml
clusterrolebinding.rbac.authorization.k8s.io "kubernetes-dashboard" created
Врешті-решт панель буде доступна за адресою https://api-<clustername-numbers.region.elb>.amazonaws.com/ui, у нашому випадку - https://api-ipeacocks-k8s-local-20s66v-1218352498.us-east-1.elb.amazonaws.com/ui

https://github.com/kubernetes/kops/blob/master/docs/addons.md#dashboard
https://github.com/kubernetes/dashboard/wiki/Access-control
https://github.com/kubernetes/dashboard/wiki/Creating-sample-user
Трохи про Dashboard я також писав в одній із перших статей про Kubernets https://blog.ipeacocks.info/2017/09/kubernetes-part-ii-setup-cluster-with.html
7.3. Heapster and Metrics Server
Heapster - програмне забезпечення, що збирає статистику роботи контейнерів та кластеру в цілому та надає REST API. Не має власної бази для збереження цієї статистики, тож потребує сторонній backend для цих цілей. Heapster також дозволяє активувати горизонтальне масштабування подів (Horizontal Pod Autoscaler), що базується на його метриках.
$ kubectl create -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/monitoring-standalone/v1.7.0.yaml
deployment.extensions "heapster" created
service "heapster" created
serviceaccount "heapster" created
clusterrolebinding.rbac.authorization.k8s.io "heapster" created
role.rbac.authorization.k8s.io "system:pod-nanny" created
rolebinding.rbac.authorization.k8s.io "heapster-binding" created
Проблема в тому, що Heapster оголошено застарілим і після релізу K8s 1.13 він взагалі не буде підтримуватись. Як заміна пропонується використання metrics-server. Планується, що він буде надавати лише головні (core) метрики, стандартизує інтерфейс доступу до них. Це буде така собі урізана версія Heapster, про деталі і причини створення якої можна прочитати за посиланнями https://blog.freshtracks.io/what-is-the-the-new-kubernetes-metrics-server-849c16aa01f4 https://brancz.com/2018/01/05/prometheus-vs-heapster-vs-kubernetes-metrics-apis/. Перед установкою останнього необхідно спочатку видалити Heapster:
$ kubectl delete -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/monitoring-standalone/v1.7.0.yaml
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/metrics-server/v1.8.x.yaml
serviceaccount "metrics-server" created
clusterrolebinding.rbac.authorization.k8s.io "metrics-server:system:auth-delegator" created
rolebinding.rbac.authorization.k8s.io "metrics-server-auth-reader" created
clusterrole.rbac.authorization.k8s.io "system:metrics-server" created
clusterrolebinding.rbac.authorization.k8s.io "system:metrics-server" created
apiservice.apiregistration.k8s.io "v1beta1.metrics.k8s.io" created
service "metrics-server" created
deployment.apps "metrics-server" created
Проте і без мінусів не обійшлось. Наразі додаток Kubernetes Dashboard вміє малювати базові графіки лише з Heapster, проте оновлення не за горами.
Після установки Heapster чи Metrics Server стане доступною команда kubectl top node/pod, котра покаже базову статистику роботу вузлів кластеру/додатків:
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-172-20-125-62.ec2.internal 32m 1% 1012Mi 26%
ip-172-20-126-59.ec2.internal 98m 4% 1650Mi 42%
ip-172-20-46-76.ec2.internal 116m 5% 1719Mi 44%
ip-172-20-59-65.ec2.internal 33m 1% 1081Mi 28%
ip-172-20-84-105.ec2.internal 33m 1% 1053Mi 27%
ip-172-20-84-26.ec2.internal 82m 4% 1626Mi 42%
$ kubectl top pod -n kube-system
https://github.com/kubernetes/kops/blob/master/docs/addons.md#monitoring-with-heapster---standalone
https://github.com/kubernetes/kops/tree/master/addons/metrics-server
https://github.com/kubernetes/kops/tree/master/addons/monitoring-standalone
7.4. Prometheus Operator + kube-prometheus
Prometheus - це open-source рішення для моніторингу, що включає в себе збір та збереження метрик, їх візуалізацію, побудову запитів на основі зібраних метрик та сповіщення. Започаткований компанією SoundCloud, проект другим вступив до CNCF альянсу (після самого K8s) в 2016 році, тому відносно легко інтегрується в Kubernetes і має багато інтеграцій з його компонентами.
Для нашої інсталяції Kops ми скористаємось напрацюваннями проекту Kube-prometheus. Kube-prometheus - це стек програм, що включає у себе наступні компоненти:
- Prometheus Operator. Надлаштування від проекту CoreOS, котре дозволяє простіше адмініструвати кластер Prometheus.
- Prometheus (HA інсталяція). Система моніторингу, де описуються різноманітні перевірки, сховище для їх збереження та трансляції повідомлень.
- Alertmanager (HA інсталяція). Обробляє сповіщення, що надходять від сервера Prometheus, та надає можливості усунення їх дублікатів, групування та маршрутизації до інших підсистем на зразок PagerDuty, Slack, email та інші. Окрім цього повідомлення, завдяки Alertmanager, можуть бути тимчасово призупинені вручну (silencing) чи автоматично (inhibition) у разі існування більш критичних повідомлень (наприклад, якщо кластер впав, то додаткові повідомлення щодо неможливості перевірити місце на диску, очевидно, будуть не дуже доречними). Для Alertmanager доступна базова web-ui панель.
- Node-exporter. Збирає інформацію щодо заліза та метрик OS на кожному вузлі кластеру K8s та імпортує її до Prometheus. Саме тому цей под присутній на всіх майстрах і воркерах K8s.
- Kube-state-metrics. На відміну від Heapster/Metrics Server, генерує нові метрики, базуючись на станах об'єктів K8s (наприклад, метрики на основі станів деплойментів, наборах реплік і т.п.). Prometheus наразі на працює з Heapster.
- Grafana. Власне внутрішні можливості Prometheus по відображенню метрик у вигляді графіків годяться більше для debug-цілей. Тож додатково буде проінстальована Grafana, в котрій Prometheus буде сконфігурований як джерело time series даних (data source).
Окрім того kube-prometheus одразу включає в себе набір готових дошок для Grafana, додаткові преконфігурації для Prometheus, що знову ж значно скорочує час налаштування старту.
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/prometheus-operator/v0.19.0.yaml
clusterrolebinding.rbac.authorization.k8s.io "prometheus-operator-default" created
clusterrole.rbac.authorization.k8s.io "prometheus-operator" created
serviceaccount "prometheus-operator" created
deployment.apps "prometheus-operator" created
namespace "monitoring" created
...
servicemonitor.monitoring.coreos.com "kube-scheduler" created
servicemonitor.monitoring.coreos.com "kubelet" created
servicemonitor.monitoring.coreos.com "prometheus" created
servicemonitor.monitoring.coreos.com "prometheus-operator" created
Після установки буде створений новий простір імен monitoring, де і розміститься частина ресурсів kube-prometheus:
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 1m
alertmanager-main-1 2/2 Running 0 1m
alertmanager-main-2 2/2 Running 0 53s
grafana-6fc9dff66-zdz6c 1/1 Running 0 1m
kube-state-metrics-5b6cf896bb-8jpbt 4/4 Running 0 48s
node-exporter-792nk 2/2 Running 0 1m
node-exporter-d246d 2/2 Running 0 1m
node-exporter-dkxx5 2/2 Running 0 1m
node-exporter-dm6pl 2/2 Running 0 1m
node-exporter-mrqtm 2/2 Running 0 1m
node-exporter-stm9l 2/2 Running 0 1m
prometheus-k8s-0 2/2 Running 1 59s
prometheus-k8s-1 2/2 Running 1 59s
prometheus-operator-7dd7b4f478-6bbb9 1/1 Running 0 1m
Окрім того деякі ресурси потраплять в default неймспейс:
$ kubectl get pods -n default | grep prometheus
prometheus-operator-784bcf6d6-hvqzm 1/1 Running 0 1m
Усі нові сервіси:
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 100.71.200.50 <none> 9093/TCP 1m
alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 1m
grafana ClusterIP 100.71.32.144 <none> 3000/TCP 1m
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 1m
node-exporter ClusterIP None <none> 9100/TCP 1m
prometheus-k8s ClusterIP 100.66.107.234 <none> 9090/TCP 1m
prometheus-operated ClusterIP None <none> 9090/TCP 1m
prometheus-operator ClusterIP None <none> 8080/TCP 1m
Доступ до яких можна отримати перекинувши порт сервісу на локальний:
$ kubectl port-forward svc/grafana -n monitoring 3000:3000
$ kubectl port-forward svc/prometheus-k8s -n monitoring 9090:9090
$ kubectl port-forward svc/alertmanager-main -n monitoring 9093:9093
Або ж створити сервіс як LoadBalancer чи виділити окремий віртуальний хост для Ingress. Prometheus має наступний вигляд:
Завдяки проекту Kube-prometheus, Grafana вже має купу готових дашбордів, тож є на що дивитись:


Alertmanager має лаконічний інтерфейс, у якому можна вимкнути повідомлення, подивитись налаштування відправлення повідомлень і це майже все:


7.4.1. Configuring Alertmanager
По-замовчуванню Alertmanager не відсилає нотифікації, адже поки не знає куди. Для виправлення цього необхідно відредагувати наступний секрет відповідно документації:
$ kubectl get secret alertmanager-main -n monitoring -o yaml
apiVersion: v1
data:
alertmanager.yaml: Cmdsb2JhbDoKICByZXNvbHZlX3RpbWVvdXQ6IDVtCnJvdXRlOgogIGdyb3VwX2J5OiBbJ2pvYiddCiAgZ3JvdXBfd2FpdDogMzBzCiAgZ3JvdXBfaW50ZXJ2YWw6IDVtCiAgcmVwZWF0X2ludGVydmFsOiAxMmgKICByZWNlaXZlcjogJ251bGwnCiAgcm91dGVzOgogIC0gbWF0Y2g6CiAgICAgIGFsZXJ0bmFtZTogRGVhZE1hbnNTd2l0Y2gKICAgIHJlY2VpdmVyOiAnbnVsbCcKcmVjZWl2ZXJzOgotIG5hbWU6ICdudWxsJwo=
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"alertmanager.yaml":"Cmdsb2JhbDoKICByZXNvbHZlX3RpbWVvdXQ6IDVtCnJvdXRlOgogIGdyb3VwX2J5OiBbJ2pvYiddCiAgZ3JvdXBfd2FpdDogMzBzCiAgZ3JvdXBfaW50ZXJ2YWw6IDVtCiAgcmVwZWF0X2ludGVydmFsOiAxMmgKICByZWNlaXZlcjogJ251bGwnCiAgcm91dGVzOgogIC0gbWF0Y2g6CiAgICAgIGFsZXJ0bmFtZTogRGVhZE1hbnNTd2l0Y2gKICAgIHJlY2VpdmVyOiAnbnVsbCcKcmVjZWl2ZXJzOgotIG5hbWU6ICdudWxsJwo="},"kind":"Secret","metadata":{"annotations":{},"name":"alertmanager-main","namespace":"monitoring"},"type":"Opaque"}
creationTimestamp: 2018-06-11T09:08:29Z
name: alertmanager-main
namespace: monitoring
resourceVersion: "697381"
selfLink: /api/v1/namespaces/monitoring/secrets/alertmanager-main
uid: 02134fee-6d57-11e8-9820-061c91e18140
type: Opaque
Попередньо необхідно розшифрувати base64, виправити, а вже потім підставити в новий секрет:
$ echo 'Cmdsb2JhbDoKICByZXNvbHZlX3RpbWVvdXQ6IDVtCnJvdXRlOgogIGdyb3VwX2J5OiBbJ2pvYiddCiAgZ3JvdXBfd2FpdDogMzBzCiAgZ3JvdXBfaW50ZXJ2YWw6IDVtCiAgcmVwZWF0X2ludGVydmFsOiAxMmgKICByZWNlaXZlcjogJ251bGwnCiAgcm91dGVzOgogIC0gbWF0Y2g6CiAgICAgIGFsZXJ0bmFtZTogRGVhZE1hbnNTd2l0Y2gKICAgIHJlY2VpdmVyOiAnbnVsbCcKcmVjZWl2ZXJzOgotIG5hbWU6ICdudWxsJwo=' | base64 --decode
global:
resolve_timeout: 5m
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'null'
routes:
- match:
alertname: DeadMansSwitch
receiver: 'null'
receivers:
- name: 'null'
Наприклад, будемо використовувати outlook.com як релей, а адресу на котру будемо надсилати листи - to-email@example.com. Конфігураційний файл alertmanager.yaml має виглядати десь наступним чином:
$ vim alertmanager.yaml
global:
resolve_timeout: 5m
route:
group_by: [Alertname]
# Send all notifications to me.
receiver: ipeacocks-alert
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'ipeacocks-alert'
routes:
- match:
alertname: DeadMansSwitch
receiver: 'ipeacocks-alert'
receivers:
- name: ipeacocks-alert
email_configs:
- to: to-email@example.com
from: from-email@outlook.com
# Your smtp server address
smarthost: smtp-mail.outlook.com:587
auth_username: from-email@outlook.com
auth_identity: from-email@outlook.com
auth_password: y0ur-v3ry-h@rd-p@ssw0rd
Створимо шаблон для майбутнього секрету:
$ cat alertmanager-secret-k8s.yaml
apiVersion: v1
data:
alertmanager.yaml: ALERTMANAGER_CONFIG
kind: Secret
metadata:
name: alertmanager-main
namespace: monitoring
type: Opaque
І оновимо вже завантажений секрет:
$ sed "s/ALERTMANAGER_CONFIG/$(cat alertmanager.yaml | base64 -w0)/g" alertmanager-secret-k8s.yaml | kubectl apply -f -
Тепер при появі нових проблем Alertmanager почне відправляти повідомлення на пошту, котрі будуть виглядати десь так:

Детальніше про роботу з секретами можна почитати тут https://kubernetes.io/docs/concepts/configuration/secret/.
Налаштування Prometheus (перевірки і тригери) та Grafana (перелік дошок та джерел даних) знаходяться в Configmaps:
$ kubectl get configmap -n monitoring
NAME DATA AGE
grafana-dashboard-definitions 8 16d
grafana-dashboards 1 16d
grafana-datasources 1 16d
prometheus-k8s-rules 1 16d
https://github.com/kubernetes/kops/blob/master/docs/addons.md#monitoring-with-prometheus-operator--kube-prometheus
https://akomljen.com/get-kubernetes-cluster-metrics-with-prometheus-in-5-minutes/
https://coreos.com/operators/prometheus/docs/latest/design.html
https://coreos.com/blog/introducing-operators.html
https://stackoverflow.com/questions/48374858/how-to-config-alertmanager-which-installed-by-helm-on-kubernetes
https://github.com/kubernetes/charts/tree/master/stable/prometheus#configmap-files
https://docs.giantswarm.io/guides/kubernetes-prometheus
https://itnext.io/kubernetes-monitoring-with-prometheus-in-15-minutes-8e54d1de2e13
https://stackoverflow.com/a/42506221/2971192
https://www.robustperception.io/sending-email-with-the-alertmanager-via-gmail/
https://github.com/prometheus/alertmanager/blob/master/doc/examples/simple.yml
7.5. EFK (Elasticsearch, Fluentd, Kibana)
EFK - комплекс програмного забезпечення, котрий організовує централізоване зберігання логів подів (додатків) та вузлів K8s. Fluentd організовує перенаправлення та обробку логів із подів до бази Elasticsearch для тривалого зберігання, а Kibana надає зручний веб-інтерфейс для їх відображення.
Можливо тип EC2, що був використаний в цій статті для установки K8s, буде замалий. Тому якщо логування справді важливе для вас - варто одразу подумати про збільшення потужностей кластера (особливо кількості RAM). Для установки ми використаємо напрацювання проекту kops, де вузли Elasticsearch описані як Stateful сети:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/kops/master/addons/logging-elasticsearch/v1.7.0.yaml
serviceaccount "elasticsearch-logging" created
clusterrole.rbac.authorization.k8s.io "elasticsearch-logging" created
clusterrolebinding.rbac.authorization.k8s.io "elasticsearch-logging" created
serviceaccount "fluentd-es" created
clusterrole.rbac.authorization.k8s.io "fluentd-es" created
clusterrolebinding.rbac.authorization.k8s.io "fluentd-es" created
daemonset.extensions "fluentd-es" created
service "elasticsearch-logging" created
statefulset.apps "elasticsearch-logging" created
deployment.extensions "kibana-logging" created
service "kibana-logging" created
Будуть підняті вузли elasticsearch (в кластері із 2-х вузлів), fluentd (поди на кожному із воркерів, представлені як DaemonSet) та kibana:
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
...
elasticsearch-logging-0 1/1 Running 0 3m
elasticsearch-logging-1 1/1 Running 0 2m
...
fluentd-es-l4xqj 1/1 Running 0 3m
fluentd-es-ngqf7 1/1 Running 0 3m
fluentd-es-r4556 1/1 Running 0 3m
kibana-logging-7db6d55fd-gdfnj 1/1 Running 0 3m
...
Бази elasticsearch житимуть на EBS дисках:
$ kubectl get pv -n kube-system
NAME CAPACITY ACCESS MODES... STATUS CLAIM... AGE
pvc-06245b3d-... 20Gi RWO Bound ...es-persistent-storage...-0 5m
pvc-34d952d5-... 20Gi RWO Bound ...es-persistent-storage...-1 3m
По-замовчуванню 20ГБ дещо замало для тривалого зберігання логів, проте їх значення зовсім не складно збільшити в описі EFK сервісу.
Через 30-40 хвилин панель буде доступною за адресою https://api-ipeacocks-k8s-local-20s66v-1218352498.us-east-1.elb.amazonaws.com/api/v1/proxy/namespaces/kube-system/services/kibana-logging/ чи через kubectl proxy. Опція з Ingress також доступна і вона найбільш елегантна в цьому випадку.
Як альтернатива є інші описи EFK кластера, де Elasticsearch інсталяція описана як оператор Kubernetes, що надає більше можливостей в адмініструванні.

https://github.com/kubernetes/kops/tree/master/addons/logging-elasticsearch
https://akomljen.com/get-kubernetes-logs-with-efk-stack-in-5-minutes/
https://akomljen.com/kubernetes-elasticsearch-operator/
https://medium.com/@carlosedp/log-aggregation-with-elasticsearch-fluentd-and-kibana-stack-on-arm64-kubernetes-cluster-516fb64025f9
http://arveknudsen.com/?p=425
https://rockyj.in/2017/04/05/kubernetes_elk.html
https://misterhex.github.io/Kubernetes-Kops-Logging-And-Monitoring/
8. DELETING KUBERNETES CLUSTER
Потужності AWS зовсім не безкоштовні, тому, якщо це були лише тести, для видалення кластеру необхідно пройти наступні процедури. У випадку, коли Kubernetes був установлений без залучення terraform:
$ kops delete cluster --name ${KOPS_NAME}
Команда покаже, що збирається видаляти, і, якщо все вірно, варто додати ключ --yes:
$ kops delete cluster --name ${KOPS_NAME} --yes
Якщо Kubernetes був установлений із залученням Terraform, то процедура дещо різниться. Інфраструктуру має видалити сам Terraform:
$ terraform plan -destroy
$ terraform destroy
А S3 відро з конфігураційними файлами - kops:
$ kops delete cluster --name ${KOPS_NAME}
$ kops delete cluster --name ${KOPS_NAME} --yes
Посилання:
https://github.com/kubernetes/kops/tree/master/docs
https://github.com/kubernetes/kops/blob/master/docs/aws.md
https://github.com/kubernetes/kops/blob/master/docs/topology.md
https://github.com/kubernetes/kops/blob/master/docs/run_in_existing_vpc.md
https://icicimov.github.io/blog/virtualization/Kubernetes-Cluster-in-AWS-with-Kops/
https://kubecloud.io/setting-up-a-highly-available-kubernetes-cluster-with-private-networking-on-aws-using-kops-65f7a94782ef
https://blog.couchbase.com/multimaster-kubernetes-cluster-amazon-kops/
https://deis.com/docs/workflow/quickstart/provider/aws/boot/
https://github.com/honestbee/terraform-workshop/blob/master/kops/README.md#kops-addon-channels
https://www.nivenly.com/kops-1-5-1/
https://kubecloud.io/upgrading-a-ha-kubernetes-kops-cluster-9fb34c441333
https://dzone.com/articles/kops-vs-kubeadm-whats-the-difference
http://blog.pridybailo.com/kubernetes-%d0%ba%d0%bb%d0%b0%d1%81%d1%82%d0%b5%d1%80-%d0%bd%d0%b0-aws/
https://www.slideshare.net/KasperNissen1/kubernetes-kops-automation-night
https://github.com/kubernetes/kops/blob/master/docs/high_availability.md
https://github.com/kubernetes-incubator/kube-aws
https://polarseven.com/running-kubernetes-aws/
https://brunocalza.me/2017/03/14/getting-started-with-kubernetes-on-aws/
https://cloudacademy.com/blog/kubernetes-operations-with-kops/
Немає коментарів:
Дописати коментар