Apache Kafka - це розробка компанії Linkedin, код якої було відкрито в 2011 році і пізніше переданий в інкубатор Apache. Сервер написаний на мові Scala, тож потребує Java-машину для роботи.
Що ж таке брокер повідомлень? Брокер повідомлень (сервер черг, система повідомлень) - це сервер, що відповідає за передачу даних від однієї програми (producer) до іншої (consumer). Брокер повідомлень допомагає абстрагуватись від того, як буде відбуватись обмін повідомленнями між програмами та зосередитись на написанні логіки програм, що працюють по обидва боки. Більш того, сервери черг дозволяють винести певну логіку на окремі сервери задля того, щоб основні потужності працювали швидко і без перебоїв, особливо якщо ця окрема логіка не термінова по часу виконання - щось на кшталт обробки фотографій для корисувачів і т.п. З іншого боку з брокерами повідомлень досить легко масштабувати споживачів (в т.ч. тимчасово), у разі якщо навантаження зросло чи ускладнилась логіка.

Існує 2 основних типи систем повідомлень (Messaging System):
- Точка-точка (point-to-point/queue). Одна чи декілька програм можуть ставити повідомлення в чергу, і відповідно одна чи більше їх читати на виході. Проте кожне повідомлення може бути прочитане лише одноразово однією із програм і надал його вже не буде в черзі. Тобто таку чергу не можуть повністю читати декілька споживачів.


- Публікація-підписка (Publish-Subscribe).На відміну від попереднього типу, повідомлення в черзі не видаляються і можуть бути прочитані повторно будь-якою кількістю клієнтів. Щось на зразок телебачення - побачити передане можуть всі і нескінченну кількість разів.


KAFKA ONE NODE SETUP
Спочатку приступимо до установки простої односерверної конфігурації. Apache Kafka доступний у вигляді бінарного архіву tgz, тому всі такі звичні речі, як налаштування користувача, від якого буде запущений демон, чи зручний запуск програми init-системою необхідно налаштовувати самостійно. Отже, створимо користувача для Kafka:
# useradd kafka -m
Та вкажемо пароль для нього:
# passwd kafka
Додамо користувача kafka до групи sudo:
# adduser kafka sudo
Після налаштування сервера черг, варто видалити права sudo та можливість логінитись цим користувачем з паролем призначеним вище. Це зроблено лише для зручності в початковому налаштуванні.
Оновимо доступні пакети та встановимо JRE:
# apt-get update
# apt-get install default-jre
Apache Kafka потребує для роботи Zookeeper, адже не має вбудованого сервісу детектування непрацюючих вузлів та обрання лідера кластеру. Хоч у нас і лише один вузол - він все рівно потрібний.
# apt-get install zookeeperd -y
Звісно, можна скористатись інстансом Zookeeper, що вже йде в дистрибутиві Kafka-и. Але це не найкращий варіант, враховуючи, що таким чином можуть з'явитись складнощі в подальшій підтримці сервісу.
Після установки, Zookeeper займе 2181 порт, роботу якого можна перевірити наступним чином:
# echo ruok | telnet localhost 2181
Відповідь у разі успіху має бути imok ("I am OK"). Завантажимо останній дистрибутив Apache Kafka, розпакуємо його та створимо усі необхідні директорії:
# su - kafka
$ mkdir -p ~/Downloads
$ wget "http://apache.volia.net/kafka/0.10.0.1/kafka_2.11-0.10.0.1.tgz" -O ~/Downloads/kafka.tgz
$ mkdir -p ~/kafka && cd ~/kafka
$ tar -xvzf ~/Downloads/kafka.tgz --strip 1
Перед запуском відредагуємо конфігураційний файл сервера черг і додамо наступне в кінець:
$ vim ~/kafka/config/server.properties
...
delete.topic.enable = true
Що дозволить видаляти теми (topics), адже по-замовчуванню це заборонено. Зробимо тестовий запуск Apache Kafka:
$ nohup ~/kafka/bin/kafka-server-start.sh ~/kafka/config/server.properties > ~/kafka/kafka.log 2>&1 &
Команда nohup дозволить процесу працювати навіть у разі, якщо користувач kafka вилогіниться із системи. Звісно, що по-хорошому для цього не завадить написати/скопіювати окремий init-скрипт, для нормального старту/зупинки сервісу.
Після цього в логах з’явиться щось на зразок наступного:
# cat ~/kafka/kafka.log
...
[2016-07-29 06:02:41,736] INFO New leader is 0 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
[2016-07-29 06:02:41,776] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
Наразі перевіримо роботу Kafka внутрішніми утилітами, що поставляються разом із дистрибутивом програми. Створимо нову чергу, що в термінології Kafka називається темою (topic) та запишемо в неї 2 повідомлення:
$ echo "Hello, World" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/null
$ echo "Test" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/null
Якщо тема TutorialTopic до цього існувала, то вона не буде перестворена.
Тепер перечитаємо чергу теми TutorialTopic із самого початку:
$ ~/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic TutorialTopic --from-beginning
Hello, World
Test
Отже, у нашому випадку поставновник - це kafka-console-producer.sh, а споживач - kafka-console-consumer.sh.
Тем може існувати багато: логічно виділяти окрему тему для окремої дії чи окремої програми.
KAFKA CLUSTER MULTI NODE SETUP
Чудово, отже наша перша конфігурація працює! Створимо щось складніше. Винесемо Zookeeper на 3 окремі вузли, що будуть обслуговувати 3 ноди Kafka. У якості адрес серверів оберемо наступні:
zk1 - 192.168.1.61
zk2 - 192.168.1.62
zk3 - 192.168.1.63
---
kafka1 - 192.168.1.51
kafka2 - 192.168.1.52
kafka3 - 192.168.1.53
Відповідно до кожного вузла потрібно додати наступне в /etc/hosts:
# vim /etc/hosts
...
192.168.1.61 zk1.me
192.168.1.62 zk2.me
192.168.1.63 zk3.me
192.168.1.51 kafka1.me
192.168.1.52 kafka2.me
192.168.1.53 kafka3.me
Або ж скористатись внутрішнім dns-сервером, якщо такий є.
Що обирати у якості віртуалізації для даних нод - власна справа кожного. Я, наприклад, останнім часом обираю контейнери LXC.
Кількість нод кластера Kafka може бути будь-якою, хоча б дві, адже Kafka сама не проводить обирання лідера і т.п. Всю роботу по функціонуванню кластера, як я вже згадував, вона делегує Zookeeper-у. І ось скільки вузлів має останній має сенс: непарна кількість попереджує появу split-brain кластеру.
Отже на перші 3 ноди ставимо Zookeeper зі стандартних репозиторіїв:
# aptitude install zookeeperd -y
Налаштовуємо кожен сервер Zookeeper-а. Для цього кожному вузлу вказуємо окремий id:
# vim /etc/zookeeper/conf/myid
1
Для першого вузла ми обрали 1, для другого і третього відповідно 2 та 3 відповідно. Окрім id в конфігураційному файлі myid не має бути нічого зайвого.
Наступний конфігураційний файл, котрий необхідно відредагувати - zoo.cfg. У ньому повинен знаходитись перелік усіх zookeeper-серверів, що будуть входити в єдиний кластер. У zoo.cfg необхідно поставити у відповідність id сервера, що ми вказали в конфігураційному файлі myid, до адреси кожного zookeper-сервера. Щось на зразок наступного:
server.<myid>=<hostname>:2888:3888
Сервер на якому відбувається зміна конфігураційного файлу zoo.cfg, має бути зазначений як 0.0.0.0. Тобто конфігураційний файл для хосту zk1 має виглядати так:
# vim /etc/zookeeper/conf/zoo.cfg
...
server.1=0.0.0.0:2888:3888
server.2=zk2.me:2888:3888
server.3=zk3.me:2888:3888
Для zk2:
# vim /etc/zookeeper/conf/zoo.cfg
...
server.1=zk1.me:2888:3888
server.2=0.0.0.0:2888:3888
server.3=zk3.me:2888:3888
А для останнього, з доменним іменем zk3.me, конфігураційний файл матиме такий вид:
# vim /etc/zookeeper/conf/zoo.cfg
...
server.1=zk1.me:2888:3888
server.2=zk2.me:2888:3888
server.3=0.0.0.0:2888:3888
Чудово. Перевантажуємо всі zookeper-вузли і читаємо лог-файли на предмет можливих помилок.
Можна перевірити хто наразі є лідером серед вузлів Zookeeper-кластеру наступною командою:
# echo stat | nc localhost 2181
Відповідь лідера на запуск команди вище, буде такою:
Zookeeper version: 3.4.8-1--1, built on Fri, 26 Feb 2016 14:51:43 +0100
Clients:
...
Latency min/avg/max: 0/2/712
Received: 22798
Sent: 22829
Connections: 3
Outstanding: 0
Zxid: 0x400000360
Mode: leader
Node count: 59
А слейва (follower-а) - такою:
Zookeeper version: 3.4.8-1--1, built on Fri, 26 Feb 2016 14:51:43 +0100
Clients:
...
Latency min/avg/max: 0/0/123
Received: 2528
Sent: 2527
Connections: 2
Outstanding: 0
Zxid: 0x400000362
Mode: follower
Node count: 59
Zookeeper - досить складний продукт, прочитати про його функціонал можна за наступним посиланням https://www.tutorialspoint.com/zookeeper/zookeeper_quick_guide.htm
Наразі налаштовуємо Apache Kafka хости для роботи в одному кластері.
Для всіх Kafka-серверів створюємо користувача kafka, завантажуємо архів з останнім дистрибутивом програми. Ми це вже робили вище. Збільшуємо ліміт максимальної кількості відкритих файлів для користувача kafka, якщо цей кластер працюватиме в продакшені:
# vim /etc/security/limits.conf
...
kafka - nofile 98304
Далі необхідно обрати унікальний id (параметр broker.id) для кожного Kafka-серверу. Значення broker.id для першого серверу я обрав 1, для другого і третього відповідно 2 і 3. Всі зміни до конфігураційного файлу Kafka першого сервера виглядатимуть так:
# su kafka
$ vim ~/kafka/config/server.properties
...
broker.id=1
listeners=PLAINTEXT://kafka1.me:9092
num.partitions=3
zookeeper.connect=zk1.me:2181,zk2.me:2181,zk3.me:2181
delete.topic.enable = true
zookeeper.connect - список Zookeper-вузлів, що будуть обслуговувати Kafka-кластер, і котрі ми налаштували вище.
listeners - адреса, на порту якої буде відкрито порт. Для кожного вузла Kafka-необхідно вказати свій хостнейм.
Конфігураційний файл другого та третього сервера будуть відрізнятись лише значенням broker.id. Далі створимо init-файл для Kafka, щоб його було зручно запускати та запускаємо кожен із них. У якості init-файлу, здається, непогано підійде цей.
Ось і все! Перевіримо роботу Kafka утилітами, що розповсюджуються разом із дистрибутивом програми. Створимо нову тему - "my-replicated-topic":
$ ~/kafka/bin/kafka-topics.sh --create --zookeeper zk1.me:2181 zk2.me:2181 zk3.me:2181 --replication-factor 2 --partitions 3 --topic my-replicated-topic
Created topic "my-replicated-topic".
Тобто тема my-replicated-topic буде поділена на 3 партиції (частини) та додатково кожна партиція матиме 2 репліки (копії). Кожна репліка буде лежати на іншому сервері, ніж еталонна партиція. Replication-factor не може бути знижений після створення теми, тому варто добре подумати наперед, яким він має бути.
Зв’язок між темами, партиціями та репліками в кластері Kafka непогано відображає цей малюнок:

На малюнку розглянуто розподіл реплік у Kafka-кластері, що складається з 5 брокерів, при умові, що тема була створена з діленням на 4 париції і фактором реплікації 3. Номер кожної репліки буде співпадати з номером брокера, на котрій вона лежить. Дуже схоже на логіку роботи Elasticsearch кластера, про який я писав раніше.
При необхідності запису нового повідомлення в чергу, Kafka спочатку запише дані в основну партицію, а вже потім дані скопіюються в репліки і лише тоді буде надіслана відповідь клієнту про успішний запис в чергу. Драйвер програми (наприклад, бібліотека), що ставить повідомлення в чергу (producer), має декілька стратегій інформування клієнта щодо результатів запису в чергу. Наприклад, вона може рапортувати про успішний запис вже у разі запису лише в основну партицію (request.required.acks=1), у разі якщо всі репліки підтягнули зміни (варіант по-замовчуванню, request.required.acks=-1) чи взагалі не чекати жодного підтвердження від сервера Kafka (request.required.acks=0).
Знову ж, як і в Elasticsearch кластері, рекомендується мати більше однієї партиції для кожної теми задля збільшення кількості операцій читання/запису (parallelism). Але цим захоплюватись також не варто - велика кількість партицій призводить до збільшення кількості відкритих файлів на кожному брокері кластера та збільшує навантаження на Zookeeper-и, адже кількість записів в ньому, щодо розміщення основних партиції і реплік до них, також збільшиться.
Поглянемо, чи нова тема (topic) справді створилась:
$ ~/kafka/bin/kafka-topics.sh --list --zookeeper zk1.me:2181 zk2.me:2181 zk3.me:2181
...
my-replicated-topic
Тепер перевіримо налаштування реплік, партицій і хто був обраний лідером для обслуговування кожної з них:
$ ~/kafka/bin/kafka-topics.sh --describe --zookeeper zk3.me:2181 zk2.me:2181 zk1.me:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:3 ReplicationFactor:2 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,1 Isr: 1,2
Topic: my-replicated-topic Partition: 1 Leader: 3 Replicas: 3,2 Isr: 2,3
Topic: my-replicated-topic Partition: 2 Leader: 1 Replicas: 1,3 Isr: 1,3
Якщо це проілюструвати, то вийде щось схоже на наступне:

Створена нами тема my-replicated-topic буде поділена на 3 партиції, кожна з яких буде лежати на окремому сервері. Перший брокер буде обраний лідером для другої партиції і на ньому ж лежатиме репліка до неї. Також на першому брокері буде репліка нульової партиції, але лідером для вже цієї партиції буде другий брокер. І т.д. для третього брокера.
Isr (in-sync replica) вказує, які репліки доступні та синхронізовані з еталонною партицією. Репліка має статус "in-sync" у разі, якщо вона може комунікувати з Zookeeper та не має багато відмінностей (не відстає) від еталонної партиції.
Лідер кожної партиції і обробляє запити на запис та читання. У разі якщо лідер впаде - репліка стане новим лідером.
Продовжимо експерименти. У новостворену чергу запишемо повідомлення:
$ echo "my replicated message" | ~/kafka/bin/kafka-console-producer.sh --broker-list kafka1.me:9092 kafka2.me:9092 kafka3.me:9092 --topic my-replicated-topic
Як бачимо з команди, програма-producer не потребує адрес Zookeeper-серверів. Це тому, що самі брокери Kafka вже звертаються самостійно до Zookeeper-кластеру, щоб дізнатись куди робити запис. До версії Kafka 0.8 логіка була дещо іншою: програма-producer мала б отримувати ситуацію по кластеру з Zookeeper напряму.
Запис відбувається просто в кінець партиції, до якої він належить.

$ ~/kafka/bin/kafka-console-consumer.sh --zookeeper zk1.me:2181 zk2.me:2181 zk3.me:2181 --topic my-replicated-topic --from-beginning
my replicated message
Читання повідомлень з черги вже відбувається трохи інакше: а саме consumer-програма спочатку звертається до Zookeeper-нод, щоб дізнатись хто є наразі лідером для кожної із партицій. Як я вже згадував, до завдань consumer-програми також входить запам'ятовування позиції (offset) до якої відбулось останнє читання:
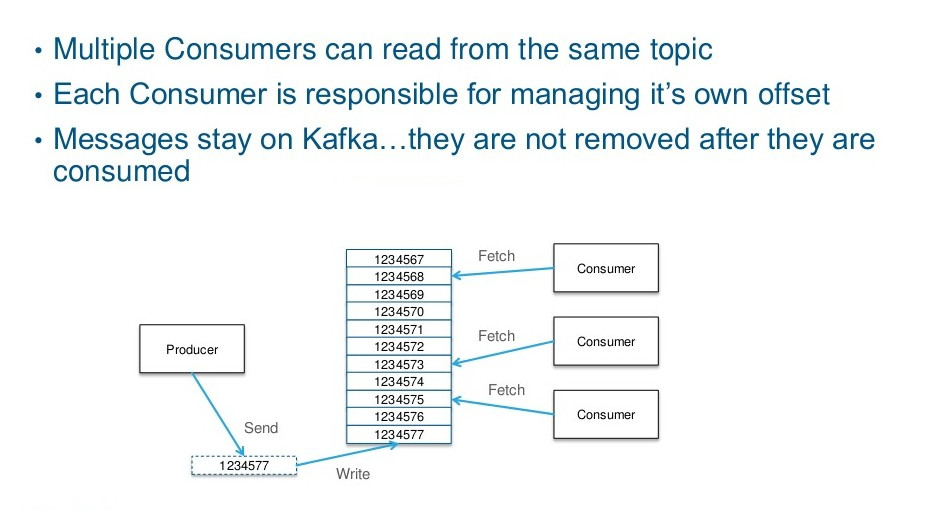
Сonsumer-програми не чистять чергу повідомлень. Черга може чиститись самостійно сервером Kafka в залежності від налаштувань, наприклад, після проходження певного часу.
Видалити тему можна наступним чином, але при умові, що в конфігураційному файлі Kafka активована опція delete.topic.enable:
$ ~/kafka/bin/kafka-topics.sh --delete --zookeeper zk3.me:2181 zk2.me:2181 zk1.me:2181 --topic my-replicated-topic
Topic my-replicated-topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
І тепер трохи про продуктивність. Як я вже згадував, пропускна здатність Kafka-и значно вище за її основних конкурентів, а саме RabbitMQ та ActiveMQ. Це досягається наступними концепціями:
- Kafka (точніше драйвери, що використовує програма для запису в Kafka) об'єднує окремі повідомлення в пакети і відправляє їх пачками.
- Читання та запис часто ведеться послідовно з диску, що впливає на швидкість віддачі та запису даних.
- Запис також ведеться пачками, тобто менші зміни обєднуються в більші і вже тоді записуються на диск, таким чином зменшуючи кількість операцій.
- Використання всієї доступної оперативної пам'яті задля кешування перед записом.
Якщо говорити про графіки, то в мережі посилаються на такі:

Посилання:
https://kafka.apache.org/documentation
https://www.digitalocean.com/community/tutorials/how-to-install-apache-kafka-on-ubuntu-14-04
http://www.michael-noll.com/blog/2013/03/13/running-a-multi-broker-apache-kafka-cluster-on-a-single-node/
http://czcodezone.blogspot.com/2014/11/setup-kafka-in-cluster.html
http://www.tutorialspoint.com/apache_kafka/apache_kafka_quick_guide.htm
https://www.tutorialspoint.com/zookeeper/zookeeper_quick_guide.htm
http://www.slideshare.net/jhols1/kafka-atlmeetuppublicv2
http://www.slideshare.net/rahuldausa/real-time-analytics-with-apache-kafka-and-apache-spark
http://www.slideshare.net/charmalloc/developingwithapachekafka-29910685
http://www.slideshare.net/popcornylu/jcconf-apache-kafka
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem
https://www.quora.com/What-are-the-differences-between-Apache-Kafka-and-RabbitMQ
https://quantifind.com/KafkaOffsetMonitor/
https://www.confluent.io/blog/apache-kafka-getting-started/
Немає коментарів:
Дописати коментар